* 수강 강의명: SQLD 자격증 대비반 - 1~2주차
[요약]
1. SQLD
- 국가 공인 자격증(필기)으로, SQL + Developer을 합친 말
- [1과목] 데이터 모델링의 이해(10문항) [2과목] SQL 기본 및 활용 (40문항) - 60/100점(90분)
└ 과목별로 정답 60% 이하 시 불합격
* 상세 링크: https://www.dataq.or.kr/www/sub/a_04.do
2. 기본 개념
① 데이터(Data): 저장이나 처리에 효율적인 형태로 변환된 정보(information)
② 데이터베이스(Database): 데이터 모음집
③ DBMS (Database Management System): 데이터베이스를 조작하는 프로그램
└ DBMS 종류는? SQLite / MySQL / ORACLE / PostgreSQL / mongoDB / MariaDB 등
* 큰 골자는 비슷하나 디테일한 문법은 프로그램마다 조금 다를 수 있음
* SQL은 오라클(SQL Server) 기반으로 출제됨
3. 데이터 모델링
1) 데이터 모델링의 이해
- 데이터 모델링이란?
└ 정보 시스템 구축을 위해 데이터 관점의 업무(비즈니스)를 분석하는 과정
└ 현실 세계의 데이터를 약속된 표기법에 의해 표현하는 과정
└ 데이터베이스를 구축하기 위한 분석 및 설계의 과정
[!] 개발을 위해서만 모델링을 하는 것이 아님
- 데이터 모델링의 특징
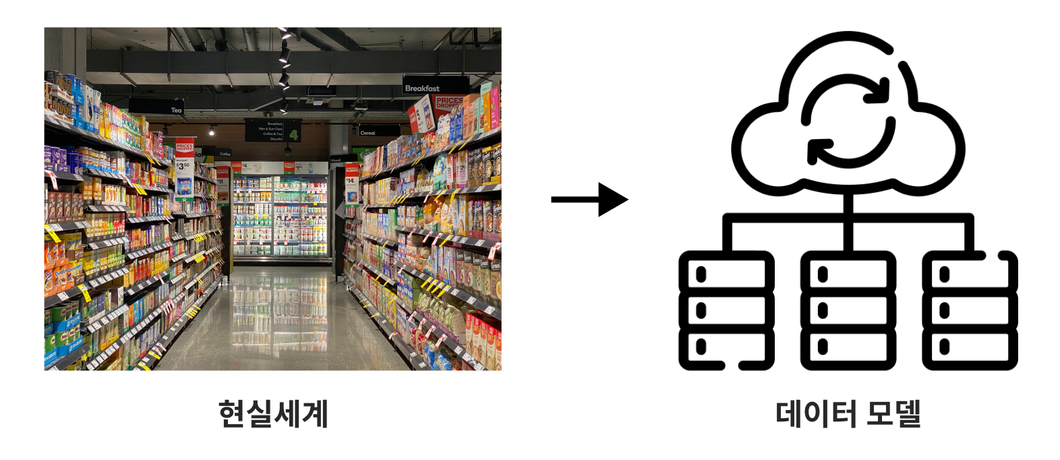
① 추상화(Abstraction): 현실세계를 일정한 형식에 맞춰 표현하는 것. 특정한 기준에 따라 나누고 구분하는 과정을 반복함
② 단순화(Simplification): 복잡한 현실세계를 약속된 규칙에 기반한 제한된 표기법이나 언어로 표현
③ 명확화(Clarity): 누구나 이해하기 쉽도록 애매모호함을 없애고 현상을 정확하게 기술하는 것
>> ①의 추상화 과정을 통해 대상은 ② 단순화되고, 이를 통해 대상이 갖는 의미가 ③ 명확화된다.
- 데이터 모델링의 단계

① 개념적 데이터 모델링(Conceptual Data Modeling)
: 데이터 요구사항을 찾고 분석하는 과정. 추상화 수준이 가장 높음 (ex. 전사 관점의 데이터 모델링)
② 논리적 데이터 모델링(Logical Data Modeling)
: 정보의 논리적인 구조와 규칙을 명확하게 표현하는 기법/ 과정. 정규화*로 데이터 모델의 독립성을 확보
③ 물리적 데이터 모델링(Physical Data Modeling)
: 논리적 데이터 모델을 컴퓨터에서 어떻게 표현할지 다루는 과정. DBMS에 테이블, 인덱스 등을 생성하는 단계
* 정규화: 논리 데이터 모델의 일관성을 확보하고, 중복을 제거하여 신뢰성 있는 데이터 구조를 얻는 방
- 데이터 모델링의 관점: 모델링된 결과물을 바라보는 3가지 관점

① 데이터 관점(What): 업무가 어떤 데이터와 관련 있는지 고민하는 관점
② 프로세스 관점(How): 업무가 실제 하는 일이 무엇이고, 무엇을 어떻게 해야 하는지 고민하는 관점
③ 데이터와 프로세스의 상관관계적 관점 (Intersection) : 업무 처리 방법에 따라 데이터는 어떤 영향을 받는지 고민하는 관점(ex. CRUD(Create, Read, Update, Delete) 분석)
2) 데이터 모델링의 중요성
- 데이터 모델링의 역할과 중요성
① 파급효과(Leverage) 줄이기
: 구체적인 내용이 변해도 큰 구조는 변하지 않도록 함. 시스템 전체 관점의 데이터 설계가 필요한 이유.
② 간결한 표현(Conciseness) 쓰기
: 시스템의 정보에 대한 요구 사항과 한계점을 가장 명확하고 간결하게 표현할 수 있는 도구로 역할
③ 데이터 품질(Data Quality) 향상시키기
: 모델링 시점에서 하기 3가지 기준을 유의하면서 데이터 품질 향상을 고민해 볼 수 있음
(1) 중복(Duplication): 여러 곳에 같은 정보를 중복해서 저장하지 않기
(2) 비유연성 (Inflexibility): 환경이 바뀌어도 데이터 사용 가능하도록 설계하기
(3) 비일관성 (Inconsistency): 데이터와 데이터 간의 상호 연관 관계를 정의해 데이터의 일관성 확인하기
- 데이터 모델링과 프로젝트 라이프 사이클
| 프로젝트 라이프 사이클 | 정보공학/구조적 방법론 | 개발 |
| 분석 | 논리 및 개념 데이터 모델링 | 프로세스 모델링 |
| 설계 | 물리 데이터 모델링 | AP 설계 |
| 개발 | DB 구축, 변겅, 관리 | AP 개발 |
| 테스트 | DB 튜닝 | AP 테스트 |
| 전환/이행 | DB 전 | AP 설치 |
- 데이터 모델링과 이해관계자
: 정보 시스템 구축에 연관된 모든 사람
3) 3층 스키마 (3-Level Schema)
- 데이터 독립성의 필요성
: 데이터 모델링에서는 일관된 형태로 데이터를 수집하는 것, 즉 데이터의 독립적 구성에 신경을 써야 함
: 데이터 독립성 확보에 따른 기대효과
① 유지보수 비용 감소 ② 유지보수 중복성 감소 ③ 데이터 복잡도 감소 ④ 요구사항 대응 개선
- 데이터베이스 3단계 구조, 3층 스키마
: 3층 스키마란, 데이터베이스를 보는 관점에 따라 데이터베이스를 기술하고 그 관계를 정의한 표준
- 3층 스키마의 구조
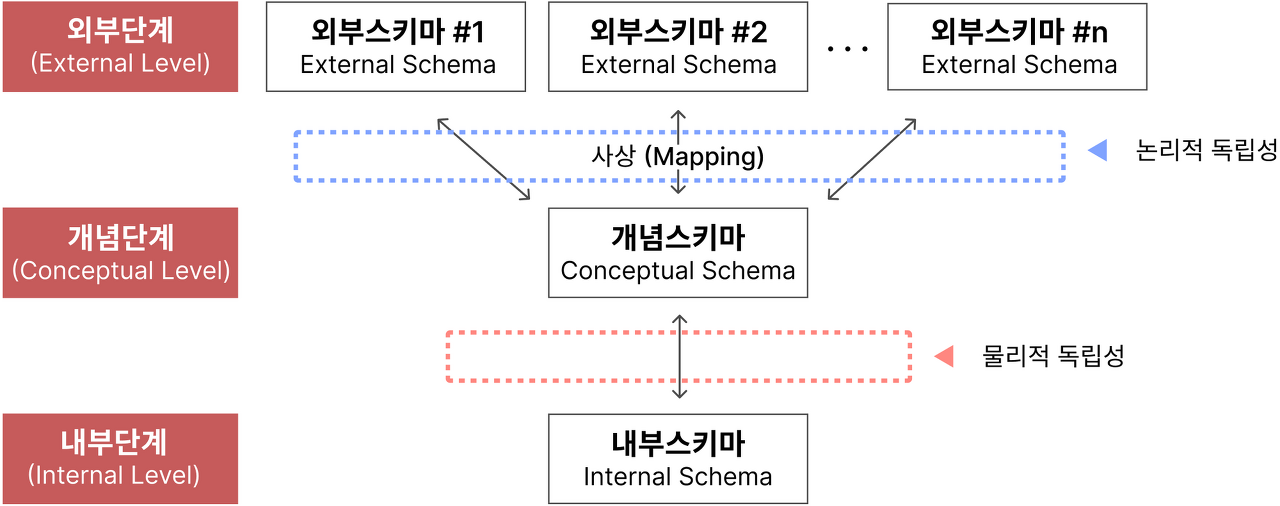
| 항목 | 관점 | 내용 | 비고 |
| 외부 스키마 | 사용자 | - 개별 사용자가 보는 DB 스키마 - 실제로 관심 있는 데이터만 볼 수 있음 |
최상위 단계 |
| 개념 스키마 | 설계자/통합 | - 데이터의 전체 구조와 관계를 설명할 수 있는 모델 - 전체 사용자 관점을 통합하고, DB 데이터와 그들의 관계를 표현 |
중간 단계 |
| 내부 스키마 | 개발자 | - DB가 물리적으로 저장된 완전히 구체적인 형식을 갖춘 모델 | 최하위 단계 |
* 각 단계별 계층을 뷰(View)라고도 부름
* 매핑(mapping)이란 각 범주간의 요청/응답을 전송하는 것.
- 데이터 독립성(Data Independence)
: 데이터베이스의 여러 레벨에서 구조를 수정할 때, 하위 레벨 스키마를 변경하더라도 상위 레벨의 스키마를 건드릴 필요가 없는 것 (영향을 미치지 않음)
: 각 단계에 따라 논리적 독립성(외부 스키마 ↔ 개념 스키마)과 물리적 독립성 (개념 스키마 ↔ 내부 스키마)이 있음
: 쉽게 말해, 데이터가 저장되는 파일의 구조를 바꿨다고 해서 (내부 스키마), 전체적인 데이터 베이스 구조/설계가 달라지거나 (개념 스키마) 응용 프로그램단 (외부 스키마)이 변경되면 안된다는 것
4) 데이터 모델링의 요소와 ERD
- 데이터 모델링의 중요 요소 3가지
① 엔터티(Entity): 업무가 관여하는 어떤 것(thing). 하나의 대상, 객체 (ex.사람 등)
② 속성(Attribute): 어떤 것(Entity)이 갖는 성격 (ex. 전화번호 , 이메일 등)
③ 관계(Relationship): 업무가 갖는 어떤 것(Entity) 간의 관계 (ex. 친구, 연인 등 )
- 데이터 모델링을 위한 ERD
: ERD(Entity Relationship Diagram)란? 데이터들의 관계를 나타낸 도표
: 작성법
엔터티 정의 및 그림 > 엔터티 배치 > 엔터티간의 관계 설정 > 관계명 서술 > 관계 참여도 기술 > 관계 필수 여부 기술
: 표기법
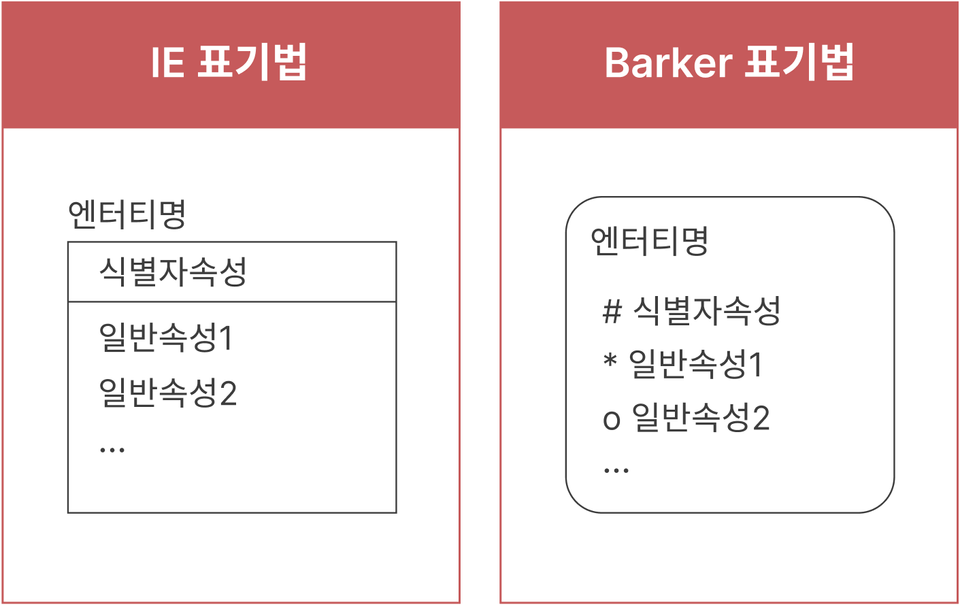
* 식별자: 엔터티의 고유한 특성
* IE는 네모 박스로, Barker는 특수문자로 표기 (# 식별자, * 필수속성, o 선택속성 등)
- 좋은 데이터 모델의 요소 (절대기준X)
ㆍ완전성(Completeness)
: 업무에서 필요로 하는 모든 데이터가 모델에 정의되어 있어야 함
ㆍ중복 제재(Non-Redundancy)
: 하나의 데이터베이스 내에 동일한 사실은 한 번만 기록해야 함
ㆍ업무 규칙(Business Rules)
: 데이터 모델링 과정에서 도출되고 규명되는 수많은 업무규칙(Business Rules)을 데이터 모델에 표현하고, 이를 해당 데이터 모델을 활용하는 모든 사용자가 공유할 수 있도록 제공해야 함 (ex. 급여 명세서 내 급여 항목별 지급 기준 등)
ㆍ데이터 재사용(Data Reusability)
: 데이터는 언제든 다시 사용할 수 있는 형태로 가공되고 보관되어야 함
ㆍ의사소통(Communication)
: 데이터 모델은 의사소통 도구로서의 역할을 해야 함
ㆍ통합성(Integration)
: 동일한 데이터 구조는 데이터를 구성하는 조직 전체에서 한 번만 정의되고, 이를 다른 영역에서 참조, 활용해야 함
[SQL 코드카타]
1. JOIN 절에 조건 넣기
[75] 자동차 대여 기록 별 대여 금액 구하기
https://school.programmers.co.kr/learn/courses/30/lessons/151141
1) 어떤 문제가 있었나
총 대여일수에 따라 할인율 테이블 내 할인율값을 매칭할 수 있는 아이디어가 안 떠오름
2) 내가 시도해본 건 무엇인가
CASE WHEN로 대여일수에 따라 문자열 정보를 추가해, 할인율 테이블과 합쳐보려고 했으나
쿼리가 지나치게 복잡해지고, 7일 미만 데이터도 NULL이 아닌 특정 문자열을 추가해서 JOIN이 어려워짐
3) 어떻게 해결했나
다른 사람 풀이를 통해 JOIN할 때도 열에 조건을 줄 수 있다는 사실을 깨달음
JOIN 테이블 뒤에 AND를 넣어서 조건 추가가 가능했음 (GROUP BY 와 HAVING 느낌?)
SELECT HISTORY_ID, ROUND(SUM(C.DAILY_FEE*(DATEDIFF(END_DATE, START_DATE)+1)*(1-IFNULL(DISCOUNT_RATE, 0)/100)),0) AS FEE
FROM CAR_RENTAL_COMPANY_RENTAL_HISTORY AS R
LEFT JOIN CAR_RENTAL_COMPANY_CAR AS C ON C.CAR_ID = R.CAR_ID
LEFT JOIN CAR_RENTAL_COMPANY_DISCOUNT_PLAN AS D ON C.CAR_TYPE = D.CAR_TYPE
AND D.DURATION_TYPE=(CASE
WHEN DATEDIFF(R.END_DATE, R.START_DATE)+1 BETWEEN 7 AND 29 THEN "7일 이상"
WHEN DATEDIFF(R.END_DATE, R.START_DATE)+1 BETWEEN 30 AND 89 THEN "30일 이상"
WHEN DATEDIFF(R.END_DATE, R.START_DATE)+1 >= 90 THEN "90일 이상"
ELSE "" END)
WHERE C.CAR_TYPE="트럭"
GROUP BY HISTORY_ID
ORDER BY FEE DESC, R.HISTORY_ID DESC
4) 무엇을 새롭게 알았나
- JOIN 절에 AND를 CASE WHEN 조건 추가가 가능했음 (비슷한 문제를 더 풀어볼 필요가 있겠음)
2. SELECT 절에 서브쿼리 넣기
[76] 상품을 구매한 회원 비율 구하기
https://school.programmers.co.kr/learn/courses/30/lessons/131534
1) 어떤 문제가 있었나
문제 요구사항에 따라 풀이하였으나 오답 처리됨
2) 내가 시도해본 건 무엇인가
WHERE로 조건절을 넣고, SELECT 절에 계산식을 넣음
SELECT YEAR(joined) YEAR,
MONTH(joined) MONTH,
COUNT(DISTINCT S.USER_ID) PUCHASED_USERS,
ROUND(COUNT(DISTINCT S.USER_ID)/COUNT(DISTINCT U.USER_ID),1) PUCHASED_RATIO
FROM USER_INFO U
LEFT JOIN ONLINE_SALE S ON U.user_id = S.user_id
WHERE YEAR(joined)='2021'
GROUP BY 1, 2
3) 어떻게 해결했나
다른 사람 풀이 확인 결과 의문점: WHERE 절로 회원가입 일자 2021년인 조건을 걸었는데,
왜 SELECT 문에서 전체 회원수 계산할 때 서브쿼리로 2021년 조건을 또 넣어야 하는 거지?
SELECT YEAR(sales_date) YEAR,
MONTH(sales_date) MONTH,
COUNT(DISTINCT S.USER_ID) PUCHASED_USERS,
ROUND(COUNT(DISTINCT S.USER_ID)/(SELECT COUNT(USER_ID)
FROM USER_INFO
WHERE YEAR(joined)='2021') ,1) PUCHASED_RATIO
FROM USER_INFO U
LEFT JOIN ONLINE_SALE S ON U.user_id = S.user_id
WHERE YEAR(joined)='2021' AND U.user_id = S.user_id
GROUP BY 1, 2
ORDER BY 1, 2
>> 문제에서 요구하는 출력 년, 월 기준이 가입일자가 아니라 판매일자 기준이었음
>> 판매일자 기준으로 출력 후 GROUP BY하면 [2021년 가입한 회원 수]는 COUNT(user_id)로만 전체 값이 계산 안 됨.
왜냐? 판매데이터가 생성된 건만 뽑아내므로! 때문에 WHERE YEAR(joined)='2021'은 전체 쿼리와 SELECT절 서브 쿼리로 총 2번 들어간 것.
>> 전체 쿼리 WHERE 절에 U.user_id = S.user_id 조건 추가가 필요한 이유는,
JOIN으로 인해 판매 데이터상 공란이 생긴 부분이 GROUP BY로 묶으면서 NULL 값 열로 합쳐짐
값이 있는 것(판매 데이터가 있는 것)만 추출하기 위해 해당 조건 추가
4) 무엇을 새롭게 알았나
- SELECT절 계산식에도 서브쿼리 적용이 가능함
- 문제에서 요구하는 바를 위해서 where절 user_id 처럼 누락된 조건 사항이 없는지 깊게 고민 필요
'TIL' 카테고리의 다른 글
| [231228] SQLD: 관계형데이터베이스, DDL, DML, TCL, DCL (1) | 2023.12.28 |
|---|---|
| [231227] SQLD: 데이터 모델링, 정규화, 데이터베이스 성능 (1) | 2023.12.27 |
| [231222] SQL: 코드카타 72~74 (0) | 2023.12.22 |
| [231221] SQL: 코드카타 71 (1) | 2023.12.21 |
| [231220] SQL: 코드카타 66~70 (1) | 2023.12.20 |


