* 수강 강의명: SQLD 자격증 대비반 - 3~6주차
[요약]
1. 데이터 모델링의 4요소
1) 엔터티 (Entity)
- 개념: 엔터티는 '개체(독립체)'라고 표현하며, 관련 있는 속성들이 모여 의미 있는 하나의 정보 단위를 이룬 것을 의미. 쉽게 말해 업무에서 쓰이는 데이터들을 분류한 그룹
- 엔터티와 인스턴스: 엔터티는 속성과 인스턴스의 집합

- 엔터티의 6가지 특징
ㆍ업무에서 필요로 하는 정보: 특정 업무에 필요한 정보여야 함
ㆍ식별 가능 여부: 업무적으로 의미를 갖는 인스턴스가 식별자에 의해 한 개씩만 존재해야 함
ㆍ인스턴스의 집합: 기본적으로 2개 인스턴스로 구성되어 있어야 함(1개만 있으면 엔터티는 집합이 아님)
ㆍ업무 프로세스에 의해 활용되어야 함
ㆍ속성을 포함해야 함: 엔터티를 설명하는 속성이 있어야 함. 주식별자만 존재하고 일반 속성이 없으면 엔터티가 아님
ㆍ관계의 존재: 다른 엔터티와의 연관성이 있어야 함
- 엔터티의 분류
| 유/무형에 따라 | 발생 시점에 따라 | ||||
| 구분 | 설명 | 예시 | 구 | 설명 | 예시 |
| 유형 엔터티 | 물리적인 형태가 존재하며 안정적이고 지속적 | 상품, 강사 | 기본/키 엔터티 (Basic Entity) |
고유한 주식별자를 갖는 독립적인 엔터티 | 고객, 상품 |
| 개념 엔터티 | 관리해야 할 개념적인 정보로 구분됨 | 코스닥 종목 | 중심 엔터티 (Main Entity |
기본 엔터티로부터 발생하며, 다른 엔터티와 관계를 통해 많은 행위 엔터티를 생성함 | 주문, 취소 |
| 사건 엔터티 | 특정한 이벤트로 종속되거나 발생됨 | 이벤트응모, 주문 | 행위 엔터티 (Activie Entity) |
두 개 이상의 기본 엔터티로부터 발생하며 내용이 자주 바뀌고 양이 많음 | 주문내역 |
- 엔터티의 이름짓기 방식
① 가능하면 업무에서 사용하는 용어 사용
② (웬만하면) 축약어(shortcut) 미사용
③ 단수 명사 사용 및 띄어쓰기 미사용
④ 모든 엔터티에서 유일한 이름 부여 (중복X)
⑤ 엔터티 생성 의미대로 이름을 부여
2) 속성 (Attribute)
- 개념: 속성은 인스턴스가 가진 어떠한 성질(성격). 업무에서 필요로 하는 인스턴스로 관리하고자 하는 의미상 더 이상 분리되지 않는 최소의 데이터 단위
- 엔터티/인스턴스/속성/속성값의 관계
ㆍ한 개의 엔터티는 두 개 이상의 인스턴스의 집합
ㆍ한 개의 엔터티는 두 개 이상의 속성으로 구성
ㆍ한 개의 속성은 한 개의 속성값을 가짐
- 속성 표기법

- 속성의 5가지 특징
ㆍ업무에서 필요로 하는 정보: 해당 업무에서 관리하고자 하는 정보여야 함
ㆍ독립성: 의미상 더 이상 분리되지 않는 그 자체로 독립성 지님(가장 작은 단위)
ㆍ인스턴트의 구성요소가 되며, 엔터티를 설명함
ㆍ정규화 이론에 기반을 두고 주식별자에 함수적 종속성*을 가짐
ㆍ하나의 속성은 한 개의 값만 가짐: 여러 개의 값이 있는 다중 값의 형태는 별도의 엔터티로 분류하여 관리
* 함수적 종속성 (Functional Dependency) : X → Y (X: 결정자, Y: 종속자)
X의 값을 알면 Y의 값을 바로 알 수 있고 X 값에 의해 Y 값이 달라질 때, 이를 Y는 X에 함수적 종속이라고 함
- 속성의 분류
| 특징에 따른 분류 | 엔터티 구성 방식에 따른 분류 | ||
| 구분 | 설명 | 구분 | 설명 |
| 기본 속성 (Basic Attribute) |
업무로부터 추출된 모든 속성. 속성 중에 가장 많음 |
PK(Primary Key) 속성 | 엔터티를 식별할 수 있는 속성 |
| 설계 속성 (Designed Attribute) |
데이터 모델링, 업무 규칙화 등을 위해 새로 만들거나 변형하여 정의하는 속성 | FK(Foreign Key) 속성 | 다른 엔터티와의 관계에 포함된 속성 |
| 파생 속성 (Derived Attribute) |
다른 속성에 영향을 받아 발생하는 속성. 보통 계산된 형태의 값 | 일반 속성 | PK, FK에 포함되지 않는 속성 |
- 도메인
└ 각 속성이 가질 수 있는 값의 범위를 의미 (범주)
└ 엔터티 내에서 속성에 대한 데이터 타입과 크기, 제약 사항 등을 지정
- 속성의 이름짓기 방식
① 가능하면 업무에서 사용하는 용어 사용
② (웬만하면) 축약어(shortcut) 미사용
③ 서술형보다는 명사형을 사용
④ 수식어 없이 명확하게 의미를 파악하도록 작성
⑤ 전체 데이터 모델에서 유일한 이름으로 작성
3) 관계 (Relationship)
- 개념: 엔터티와 인스턴스 사이가 논리적으로 혹은 존재의 형태 행위로 서로에게 연관성이 부여된 상태
- 관계 페어링(Relationship Paring)
: 엔터티 안에 인스턴스가 개별적으로 연결되어 있는데, 이 관계를 '페어링'이라고 부름
- 관계의 분류
└ 종류 (목적에 따라)
① 존재에 의한 관계: 소속/포함의 형태 (ex. 부서-사원)
② 행위에 의한 관계: 행동/행위의 결과 (ex. 고객-주문)

└ 통합 모델링 언어(UML, Unified Modeling Language)
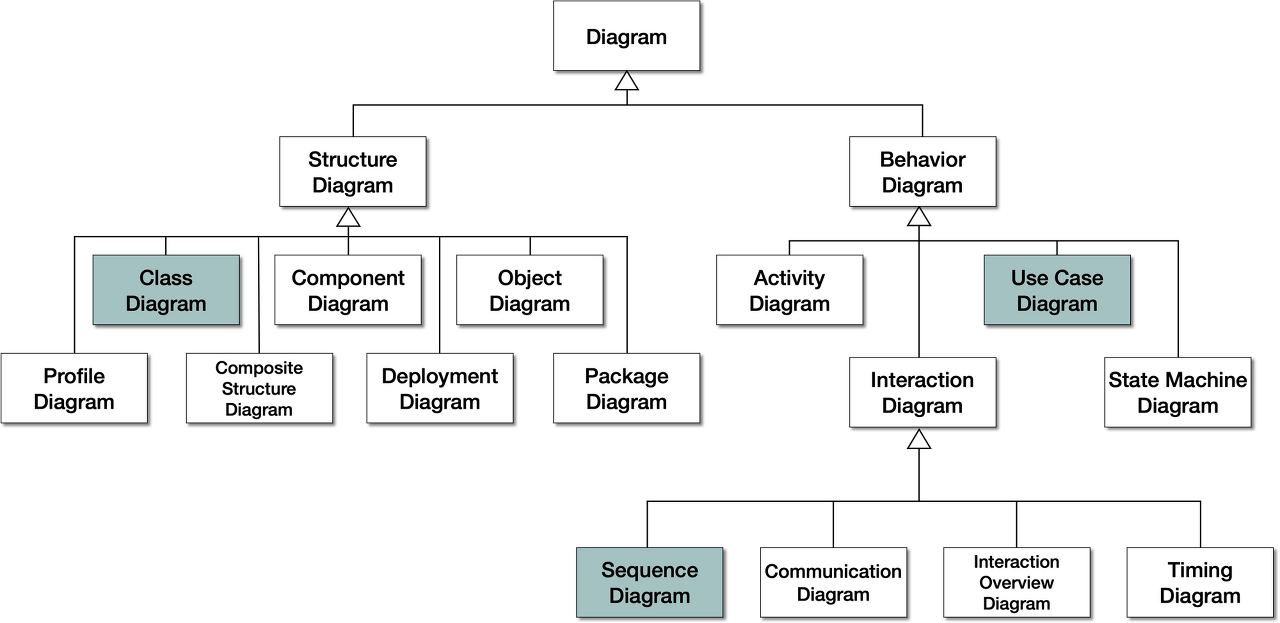
UML는 소프트웨어 공학에서 사용되는 표준화된 범용 모델링 언어로 여러 종류의 UML 다이어그램을 통해 시각화된 형태의 모델링 된 결과를 살펴볼 수 있음
[!] UML 클래스 다이어그램과 ERD(Entity Relationship Diagram) 의 차이점은?
UML 클래스 다이어그램은 클래스 간 연관관계(Association)과 의존관계(Dependency)를 명확히 표현함. 반면 ERD는 존재적 관계와 행위에 의한 관계를 구분하지 않음.
- 관계의 표기법
ㆍ관계명 (Membership)
: 엔터티가 관계에 참여하는 형태를 지칭하며, 각 관계명에 따라 두 개의 관계명을 가짐. (ex. 포함한다, 소속된다)

ㆍ관계 표기법
└ 개수및 식별/비식별

└ 관계선택사양(Optionality)
① 필수 관계(Mandatory Membership): 상대 엔터티에 대해 조건을 만족하는 엔터티가 반드시 존재할 경우 표시
② 참여 관계(Optional Membership): 상대 엔터티에 대해 조건을 만족하는 엔터티가 존재할 수도, 아닐 수도 있는 경우 표시

ㆍ 관계차수 (Degree / Cardinality) ★★★
└ 두 개의 엔터티 간의 관계에서 참여자의 수를 표현하는 것
① 1:1 (ONE TO ONE) 관계 표시
: A Entity에 존재하는 데이터 1개와 관계되는 B Entity에 존재하는 데이터의 개수도 1개인 경우를 1:1 관계라고 함
: ex. 웹서비스 유저와 프로필 관계: 각 1개 데이터만 매칭

② 1:M (ONE TO MANY), 1:N 관계 표시
: A Entity에 존재하는 데이터 1개와 관계되는 B Entity에 존재하는 데이터의 개수가 여러 개인 경우(한 방향만 해당)
: ex. 웹서비스에 댓글과 게시글: 하나의 게시글에 댓글은 있거나 없어도 되지만 반드시 게시글에 있어야 함
관계를 1:N 관계라고 합니다.

③.M:M(MANY TO MANY), M:N 관계 표시
: A Entity에 존재하는 데이터 1개와 관계되는 B Entity에 존재하는 데이터의 개수가 여러 개고, 반대의 경우도 동일한 경우
: ex. 웹서비스 좋아요 기능에서 유저와 게시글: 하나의 게시글에 여러 유저가 좋아요, 유저는 여러 게시글에 좋아요 가능

ㆍ관계 정의 시 체크 사항
└ 두 엔터티 사이에는 관심 있는 연관 규칙이 존재하는지 여부
└ 두 개의 엔터티 사이에 정보의 조합이 발생하는지 여부
└ 업무 기술서, 장표에 관계 연결에 대한 규칙이 있는지 여부
└ 업무 기술서, 장표에 관계 연결을 가능하게 하는 동사(Verb)가 있는지 여부
ㆍ관계 읽기
└ 기준(Source) 엔터티는 한 개(One) 혹은 각(Each)으로 읽음
└ 대상(Target) 엔터티의 관계 참여도 개수(하나, 하나 이상)로 읽음
└ 관계 선택 사양에 따라 관계 이름을 읽음

(연습)


4) 식별자 (Identifier)
- 개념: 엔터티의 인스턴스를 구분 가능하게 만들어주는 대표 속성. 하나의 엔터티엔 반드시 하나의 유일한 식별자가 존재
- 특징: 유일성, 최소성(유일성을 만족하는 최소의 수), 불변성, 존재성(NULL 허용X)
- 분류
| 대표성 여부 | 스스로 생성 여부 | 단일속성 여부 | 대체 여부 | ||||
| 주 식별자 | 보조 식별자 | 내부 식별자 | 외부 식별자 | 단일 식별자 | 복합 식별자 | 본질 식별자 | 인조 식별자 |
| - 인스턴트 구분 가능 - 다른 엔터티와 참조관계 연결 가능 |
- 인스턴트 구분 가능 - 다른 엔터티와 참조관계 연결 불가 |
- 엔터티 내부정의 | - 다른 엔터티에서 받아오는 식별자 | - 하나의 속성으로 구성 | - 둘 이상의 속성으로 구성 | - 업무에 의해 생성 | - 인위적으로 생성 |
* 어커런스(Occurence)란?
인스턴스(Instance)와 같은 의미. 데이터베이스에 구체적이고 실제적인 정보를 담고 있는 실제 데이터
- 표기법

- 도출 기준
ㆍ업무에서 자주 사용하는 속성으로 설정
ㆍ명칭, 내역 등 특정 고유명사는 주식별자로 사용하지 않음
ㆍ주식별자에 너무 많은 속성이 포함되지 않도록 함
- 식별자 관계와 비식별자 관계
ㆍ 결정요인: 외부 식별자(Foreign Identifier) - 자기 엔터티에 필요한 속성이 아니라 다른 엔터티와 관계를 통해 생성되는 속성
└ 식별자 관계: 자식 엔터티가 부모 엔터티의 주식별자를 본인의 주식별자로 사용하는 경우 (빈 값이 없어야 함)
└ 비식별자 관계: 자식 엔터티가 부모 엔터티의 주식별자를 일반 속성으로만 사용하는 경우
* 식별자 관계로만 설정할 경우 데이터 모델 복잡성이 증가되어 오류 발생 가능성이 커짐
| 분류 | 식별자 관계 | 비식별자 관 |
| 목적 | 강한 연결관계의 표현 | 한 연결관계의 표현 |
| 자식 주식별자 영향 | 자식 엔터티의 주식별자의 구성에 포함 | 자식 엔터티의 일반 속성에 포함 |
| 표기법 | 실선(IE) / 버티컬바(Barker) | 점선(IE) |
| 고려사항 | - 반드시 부모 엔터티에 종속 - 자식 주식별자 구성에 부모 엔터티의 주식별자 속성이 필요한 경우에 사용 - 상속 받은 주식별자 속성을 타 엔터티에 이전 필요 |
- 약한 종속 관계 - 자식 주식별자 구성을 독립적으로 구성할 경우 사용 - 자식 주식별자 구성에 부모 주식별자 부분 필요 - 상속 받은 주식별자 속성을 다른 엔터티에 차단 필요 - 부모 쪽의 관계 참여가 선택 관계 |

④ 데이터베이스 용량과 트랜잭션 유형에 따라 반정규화 수행
⑤ 이력 모델, PK / FK, 슈퍼 타입 / 서브 타입의 조정: 성능 우수 순으로 칼럼 순서 조정
⑥ 성능 관점에서 데이터 모델 검증
- 정규화의 이점
ㆍ데이터의 유연성: 종속성이 강한 데이터를 분리하여 독립된 개념으로 정의하기 때문에 높은 응집도*와 낮은 결합도* 원칙에 충실
ㆍ데이터의 재활용성: 데이터 개념 세분화의 결과로 개념에 대한 재활용 가능성 증가
ㆍ데이터의 중복 최소화: 식별자가 아닌 속성이 한 번만 포함되기 때문에 데이터 중복 최소화
* 응집도: 요소들이 서로 관련되어 있는 정도 (높을수록 품질이 좋음)
* 결합도: 요소들 간의 상호 의존하는 정도 (높으면 시스템 구현 및 유지보수가 어려움)
- 기본 용어
| 용어 | 설명 |
| 정규화(Normalization) | DBMS 테이블 삽입, 삭제, 수정 과정에서 이상(Anomaly) 현상의 발생을 최소화하기 위해 작은 단위로 테이블을 나눠가는 과정 |
| 정규형 (NF: Normal Form) | 정규화된 결과물 |
| 함수적 종속성 (FD: Functional Dependency) |
칼럼 값(A)을 알 경우 다른 칼럼 값(B)도 알 수 있다면 칼럼 B는 칼럼 A에 함수 종속성을 갖는다고 표현 |
| 결정자(Determinant) | 함수적 종속성에서 특정 속성을 결정짓는 요소 (ex. 학번은 학생 이름을 결정) |
| 종속자(Dependent) | 함수적 종속성에서 결정자에 종속되는 값 (ex. 학생 이름은 학번에 종속) |
| 다치 종속 (MVD: MultiValued Dependency) |
결정자 칼럼 A에 의해 칼럼 B의 값을 다수 알 수 있을 때, 칼럼 B는 칼럼 A에 다치종속되었다고 표현 |
2) 정규화 이론 - 정규화 유형과 함수적 종속성
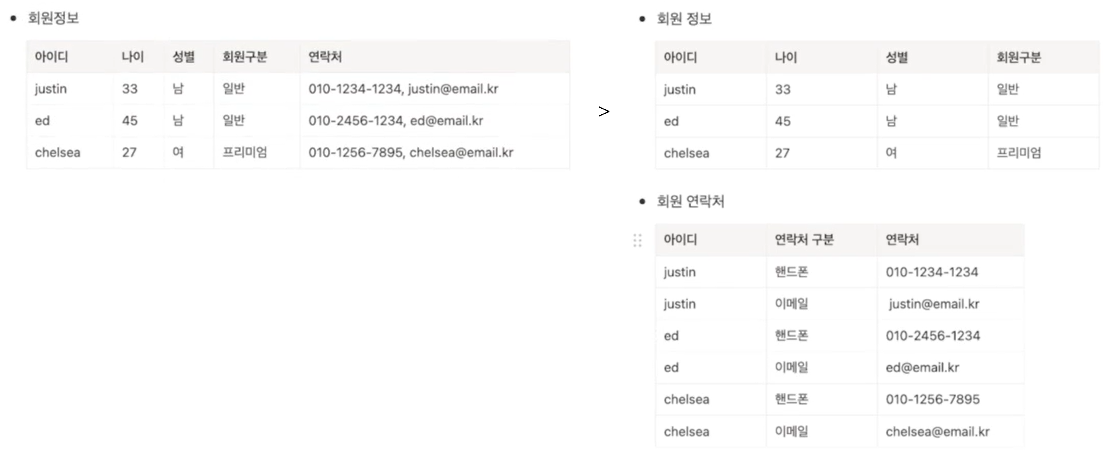
(1) 제1정규화(1NF)
- 하나의 속성에는 하나의 속성 값만 넣는 것 (연락처 속성에는 핸드폰 번호 or 이메일 하나만 넣기)
- 한 속성에 여러 개의 속성이 포함되어 있거나 같은 유형의 속성이 여러 개로 나눠져있는 경우 해당 속성을 분리
(2) 제2정규화(2NF)
- 제1정규화를 만족시키고, PK(주식별자)가 아닌 모든 칼럼은 PK 전체에 종속되는 것
- PK 중 전체가 아닌, 일부의 속성에만 종속되는 칼럼이 있다면 분리 필요
└ 반복된 데이터 일부를 갱신할 때 전체가 동일하게 갱신되지 않아 데이터 불일치가 되는 '갱신 이상(Modification Anomaly)' 문제 발생 가능성 때문!
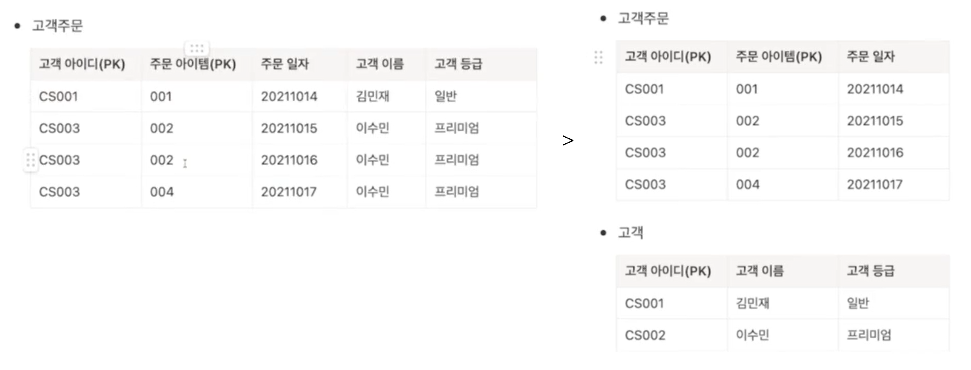
> 각 주 식별자에 종속되는 칼럼만 분리
(3) 제3정규화(3NF)
- 제2정규화를 만족시키고 일반 속성 간에도 함수 종속 관계가 존재하지 않아야 함
- 일반 속성들 간의 종속 관계가 존재한다면 분리해야 함
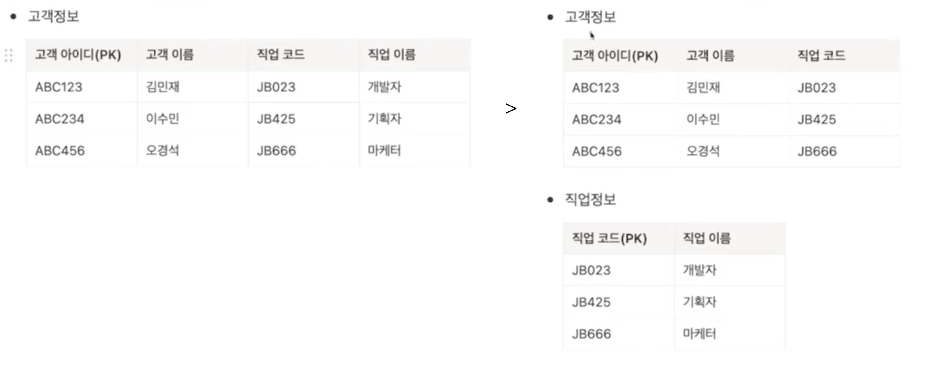
3) 반정규화
- 개념: 성능 향상을 목적으로 정규화를 수행하지 않은(즉 중복을 허용한) 모델을 지칭하는 말로, 역정규화라고도 함
- 반정규화가 필요한 상황은? 보통 '조회' 성능 향상을 위해 활용
① 데이터를 조회할 때 디스크 I/O량이 많아 성능이 저하되는 경우
② 테이블 간 경로가 멀어 조인으로 인한 성능 저하가 예상되는 경우
③ 칼럼을 계산하여 읽을 때 성능이 저하될 것이라고 예상하는 경우
- 절차
① 반정규화 대상 조사 ② 다른 방법 유도 검토 ③ 반정규화 적용
- 기법
① 테이블 반정규화
└ 테이블 병합: 1:1 관계 테이블 / 1:M 관계 테이블 / 슈퍼&서브 타입 테이블 병합 - 조인 연산 제거
└ 테이블 분할: 수직 분할(구조변화 O ex. 업데이트가 잦은 칼럼 분리) / 수평 분할(구조변화 X ex. 년/월/일 테이블 분할)
* 정규화 법칙이 아닌 것으로 분할하면 반정규화
└ 테이블 추가: 중복 테이블(서버나 업무가 다른 경우) / 통계 테이블(계산식 적) / 이력 테이블(마스터 테이블 존재) / 부분 테이블 추가(자주 조회하는 칼럼만 별도 추출)
② 칼럼 반정규화
- 중복 칼럼 추가 / 파생 칼럼 추가 / 이력 테이블 칼럼 추가 / PK에 의한 칼럼 추가 / 응용 시스템의 오작동을 위한 칼럼 추가
* 복합키(Composite Key): 기본키로 사용할 수 있는 칼럼이 없을 때 2개 이상의 키를 합쳐 하나의 기본키로 활용하는 것
③ 관계 반정규화
- 중복 관계 추가: 조인 경로를 줄여서 성능 향상. A > B > C 형태의 조인을 A > C로 줄이는 것.
3. 데이터베이스의 구조와 성능
1) 대량 데이터에 따른 성능
: 데이터 모델 설계가 아무리 잘 되어 있어도 대량 처리 시 성능 저하가 발생 > 분할을 통해 해결 가능
(cf) 데이터베이스 입출력(I/O) 시 테이블 내 모든 행은 블록 단위로 디스크에 저장
> 칼럼이 많아지면 하나의 행이 여러 블록에 걸쳐서 저장되며 성능이 저하됨

- 대용량 데이터로 인한 대표적인 성능 저하 현상
└ 하나의 행 조회 시 2개 이상 블록을 불러와 성능 저하에 영향을 주는 사례
① 로우 체이닝 (Row Chaining)
: 행 데이터가 너무 길어서 2개 이상 블록에 저장된 형태
② 로우 마이그레이션 (Row Migration)
: 데이터 블록 수정 발생 시 기존 블록에 수정 사항을 저장하지 못하고 다른 블록의 빈 공간에 저장되는 방식
(cf) 데이터베이스 파티셔닝(Partitioning)
하나의 DBMS에 많은 테이블이 저장되면서 성능과 용량에 이슈가 발생해, 테이블을 작은 단위로 쪼개 관리하는 ;파티셔닝 기법이 발생. 큰 테이블을 다수의 엔터티로 물리적 분할을 하나, 접근 시 분할된 테이블로 인식하지 못하는 특징이 있음
- 성능 향상을 위한 테이블 분할 방법
① 수평 분할: 행 단위로 요소를 분할하여 디스크의 입/출력 비용을 감소시키는 방법
└ 한 테이블에 많은 수의 칼럼이 있는 경우 사용
└ 테이블 수평 분할을 통해 모든 칼럼을 조회하지 않고, 필요한 칼럼만 조회하여 디스크 입/출력 감소
② 수직 분할: 칼럼 단위로 요소를 분할하여 디스크의 입/출력 비용을 감소시키는 방법
ㆍ범위 분할(RANGE PARTITION): 특정 기간을 중심으로 분할하는 범위 파티서닝
ㆍ목록 분할(LIST PARTITION): 테이블 내 리스트를 활용하여 분할하는 파티셔닝(지역, 성별 등)
ㆍ해시 분할(HASH PARTITION): 약속된 규칙에 따라 해싱 알고리즘(함수)를 적용해 테이블 분리
└ 장점: 부하 감소, 특정 파티션에 데이터가 집중될 수 있는 범위 분할 단점 보완, 데이터 대랑 처리 시 경합 감소
└ 단점: 데이터 관리가 어려움 (보관주기에 따른 삭제 기능, 데이터 저장 경로 파악 등)
ㆍ합성 분할(COMPOSITE PARTITIONING) : 상기 3개 분할 방식을 섞는 것(ex. 범위 분할 후 해시 분할 적용)
2) 데이터베이스의 구조와 성능
(1) 슈퍼타입 / 서브타입 모델
- 데이터 모델링에서 자주 쓰이는 기법으로 데이터 특징에 따라 슈퍼타입은 공통 속성, 서브타입은 개별 속성을 포함

| 구분 | 슈퍼타입 (Single / All in One) |
서브타입 (Plus / Super + Sub) |
개별타입 (OneToOne + 1:1) |
| 설명 | - 하나의 테이블로 변환 - 테이블을 싱글 테이블로 구성 |
- 각 서브타입 테이블에 공통된 수퍼타입을 보유 | - 슈퍼타입과 서브타입을 각각 개별 테이블을 만드는 것 - 슈퍼/서브 테이블 모두 생성 |
| 특징 | 하나의 테이블 | 각각의 서브타입 테이블 | 슈퍼 서브 각각의 테이블 |
| 확장성 | 나쁨 | 보통 | 좋음 |
| 조인 성능 | 우수함 | 나쁨 | 나쁨 |
| I/O 성능 | 나쁨 | 좋음 | 좋음 |
| 관리 용이성 | 좋음 | 좋지 않음 | 좋지 않음 |
(2) 인덱스 특성을 고려한 PK / FK 데이터베이스 성능 향상
- PK 순서와 성능 사이의 관계
: 테이블에 발생되는 트랜잭션 조회 패턴에 따라 복합 PK 칼럼 순서가 성능에 영향을 줄 수 있음
: 자주 쓰는 조합을 앞 순서에 배치하거나 필터링(where) 조건을 뽑는게 복잡한 칼럼을 뒤로 배치
(ex.) 연도+학기 조합이 자주 출력될 경우, 칼럼 순서 변경으로 성능 개선 가능

- FK와 테이블 인덱스 구성 사이의 관계
: 외래키(FK)에 대한 인덱스를 미리 생성해두면 조인 과정에서 성능 저하를 막을 수 있음
3) 분산 데이터베이스와 성능
(1) 분산 데이터베이스
- 개념: 분산되어 있는 데이터베이스 시스템을 하나의 가상 시스템으로 사용할 수 있도록 한 것. 물리적으로는 분산돼 있지만 논리적으로는 하나의 데이터베이스로 존재
- 분산 데이터베이스가 되기 위해 필요한 6가지 투명성(Transparency)
: 분할 투명성 / 위치 투명성 / 지역 사상 투명성 / 중복 투명성 / 장애 투명성 / 병행 투명성
- 적용 방법
: 업무 구성에 따른 아키텍처가 어떤 형태로 구성되어 있는지 등을 충분하게 고려하여 적용해야 함
: 개발 및 처리 비용이 증가하고, 응답 속도 또한 원하는 수준으로 개선되지 않을 수 있기 때문
- 장단점
└ 장점: 용량 확장, 신뢰성&가용성, 효용성&융통성, 응담속도 및 통신비용 개선 등
└ 단점: 개발 및 처리 비용 증가, 오류 잠재성 증가, 불규칙한 응답 속도, 통제 어려움 등
(2) 분산 데이터베이스의 활용 방향성 및 적용 기법
- 활용 방향성: 위치 중심 > 업무 필요에 의한 분산 설계를 많이 사용중
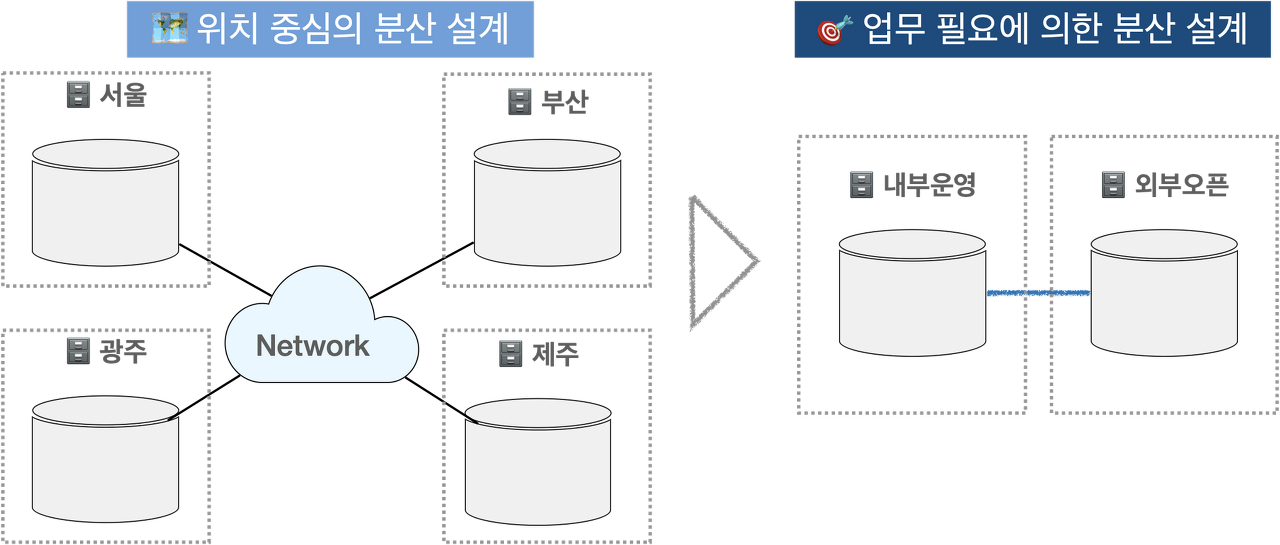
- 적용 기법
① 테이블 위치(Location) 분산 : 위치(지역)에 따른 분산
② 테이블 분할(Fragmentation) 분산: 수평/수직 분할로 쪼개서 분산
③ 테이블 복제(Replication) 분산: 전체 테이블은 두고, 부분만 복사(부분복제)하거나 전체 복사(광역복제)해서 분산
④ 테이블 요약(Summarization) 분산
└ 분석 요약(Rollup Summarization): 동일한 테이블 구조 및 내용을 가진 테이블을 이용해 통합 데이터 산출
└ 통합요약(Consolidation Summarization): 분산된 다른 내용의 데이터를 이용해 통합 데이터 산출
[SQL 코드카타 77~83]
1) 어떤 문제가 있었나
2) 내가 시도해본 건 무엇인가
3) 어떻게 해결했나
4) 무엇을 새롭게 알았나
- SQL에서 length(칼럼명) 함수를 통해 문자열의 글자수(음절 기준)를 구할 수 있음'TIL' 카테고리의 다른 글
| [231229] SQLD: JOIN, 집합연산자, 서브쿼리, 그룹함수, 윈도우함수 (1) | 2023.12.29 |
|---|---|
| [231228] SQLD: 관계형데이터베이스, DDL, DML, TCL, DCL (1) | 2023.12.28 |
| [231226] SQLD: 기본개념 및 데이터 모델링 & SQL: 코드카타 75~76 (1) | 2023.12.26 |
| [231222] SQL: 코드카타 72~74 (0) | 2023.12.22 |
| [231221] SQL: 코드카타 71 (1) | 2023.12.21 |



