과제 목표
- 주어진 데이터는 1년 동안 Github public repository(개발자들의 코드 저장소)의 푸시 횟수입니다.
└ Github의 공개 저장소에 대한 기록은 모두에게 공개되어 있으며, Bigquery에 데이터베이스 형태로도 저장되어 있습니다.
- 아래 데이터는 2019년 2월 1일 ~ 2020년 1월 14일, 약 1년간 각 일자별 Push(코드 업데이트) 횟수입니다
└ 각 개인 별 데이터는 취합되었기 때문에 확인이 어려우며, 전 세계의 데이터이기 때문에 하루에도 수십만회 Push가 이루어집니다.
- 본 과제의 목표는 요일 별 Push 횟수에 유의미한 차이가 있는지 확인하는 것입니다.
└ 이를 위한 데이터의 기본적인 전처리가 과제이며, 실제 통계 분석은 예시로 제공됩니다.
Question 1: 날짜 전처리
## 날짜를 변환
df['log_date'] = pd.to_datetime(df['log_date'], format='%y-%m-%d')
## 변환된 날짜 칼럼으로부터 요일dayofweek을 숫자로 추출
df = df.assign(day_of_week = df['log_date'].dt.dayofweek)
df.info()
- 편의성 때문에 df.log_date 식으로 표기도 가능하나 정석은 df['log_date']
- 칼럼 할당할 때는 df['day_of_week'] = ~~ 으로 하는 것보다는 assign이 바람직
- 요일별 데이터를 구하는 dayofweek는 weekday로도 대체 가능

Question 2: Groupby로 통계량 집계
## 요일별 푸시 횟수의 평균과 중간값 추출
push_count_by_dow = df.groupby('day_of_week')['push_count'].agg(['mean', 'median'])
push_count_by_dow = push_count_by_dow.sort_index()
display(push_count_by_dow)
- 다중 집계 함수를 사용할 대는 agg() 함수 이용

Question 3: Bar chart 시각화
## 요일별 평균을 bar chart로 시각화
bar_data = push_count_by_dow["mean"].reset_index() #정답은 push_count_by_dow["mean"].plot.bar()
plt.bar(bar_data["day_of_week"], bar_data["mean"], width=0.5)
plt.xticks(rotation=90)
plt.xlabel('day_of_week')
plt.ylabel('mean')
plt.title('Mean by Day_Of_Week')
plt.show()

Question4(Optional): 아웃라이어 제거
## 함수 기반으로 z score 기반의 이상치 탐지
def z_score_outlier_remover(df:pd.DataFrame, threshold:float) -> pd.DataFrame:
"""
z-score가 Threshold가 넘는 값들을 이상치로 판단하고 제거.
단, 이상치가 제거될 때마다 평균과 분산이 바뀌므로 이상치가 존재하지 않을 때까지 무한 반복
"""
total_outlier_count = 0
if threshold <= 0:
raise ValueError("Threshold must larger than zero")
while True:
## 평균과 표준 편차를 집계
m = df['push_count'].mean()
s = df['push_count'].std()
## push_count의 각 요소가 이상치인지를 나타내는 Boolean series 생성
## pd.Series 이건 빼도 무관
## 정답은
## ser_outlier_bool = (df.push_count - m).abs() > (threshold*s)
ser_outlier_bool = pd.Series(abs((df['push_count'] - m) / s) > threshold, name='Outlier')
## 이상치의 숫자를 집계
## 정답은
## outlier_count = ser_outlier_bool.sum()
outlier_count = df[ser_outlier_bool].count()['push_count']
## 이상치가 존재한다면 그 숫자를 세고, 제거
if outlier_count > 0:
total_outlier_count += outlier_count
## 정답은
## df = df[~ser_outlier_bool]
df = df.drop(df[ser_outlier_bool==1].index , axis=0)
## 이상치가 존재하지 않으면
else:
## 제거한 이상치가 1개 이상이라면 출력하고 종료
if total_outlier_count > 0:
print(f"The number of outliers(z-score > {threshold}): {total_outlier_count}")
break
return df
- 방어 코드(if threshold <= 0: raise ValueError("Threshold must larger than zero")가 있어야 컴퓨터가 제대로 작동함
- 코드 작성 시 독스트링이나 타입힌트을 표시해주는 것이 좋음
└ 타입힌트: 함수명 옆에 타입을 표시해주는 것. ex. def sth(df:pd.DataFrame, threshold:float) -> pd.DataFrame:
└ 독스트링(docstring): 함수 시작 부분에 함수 인터페이스를 설명하는 문자열. 따옴표(""")나 작은 따옴표 세 개(''')로 표시
- 표준편차는 numpy인지 pandas 인지에 따라 값이 달라져서 기준을 명확하게 하는 것이 좋음 (자유도에서 -1 여부)
- 통상 데이터가 많으면 numpy가 2배 정도 빠름
- 변수 앞에 ~를 넣으면 Ture & False 값이 반전됨
▶ 요일별 이상치
## 요일 별로 이상치를 제거
threshold = 3
n_before = len(df)
df_outlier_removed_list = []
for day_of_week, group in df.groupby("day_of_week"):
print(f"Day of week: {day_of_week}: Started")
group_outlier_removed = z_score_outlier_remover(group, threshold)
df_outlier_removed_list.append(group_outlier_removed)
print(f"Day of week: {day_of_week}: End\n")
## 원본 데이터 대체
df = pd.concat(df_outlier_removed_list)
n_after = len(df)
outlier_ratio = (n_before - n_after) / n_before * 100
print(f"Outlier removed: {n_before} -> {n_after}({outlier_ratio:.2f}%)")

기타: 통계 결과
▶ ANOVA
F, p_value = stats.f_oneway(*[group.push_count for dow, group in df.groupby('day_of_week')])
print(f"F statistics: {F:.4f}")
print(f"P-value: {p_value:.4f}")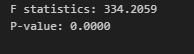
▶ Assumption test
df['residual'] = df['push_count'] - df.groupby('day_of_week').push_count.transform('mean')
df['std_resi'] = (df['residual'] - df['residual'].mean()) / df['residual'].std()
## 날짜 순으로 정렬
df = df.sort_values("log_date")
## 이동평균 생성
df = df.assign(push_count_ma = df.push_count.rolling(28).mean())
# MA plot
plt.plot(df.log_date, df.push_count_ma)
plt.xticks(rotation=20)
plt.show()
# QQ plot
sm.qqplot(df['std_resi'], line='45')
plt.xlabel("Theoretical Quantiles")
plt.ylabel("Standardized Residuals")
plt.show()
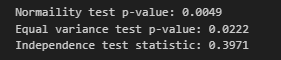
# normality
w, pvalue = stats.shapiro(df.residual)
print(f"Normaility test p-value: {pvalue:.4f}")
# equal variance
w, pvalue = stats.bartlett(*[group.residual for dow, group in df.groupby('day_of_week')])
print(f"Equal variance test p-value: {pvalue:.4f}")
# independency
d = durbin_watson(df.residual)
print(f"Independence test statistic: {d:.4f}")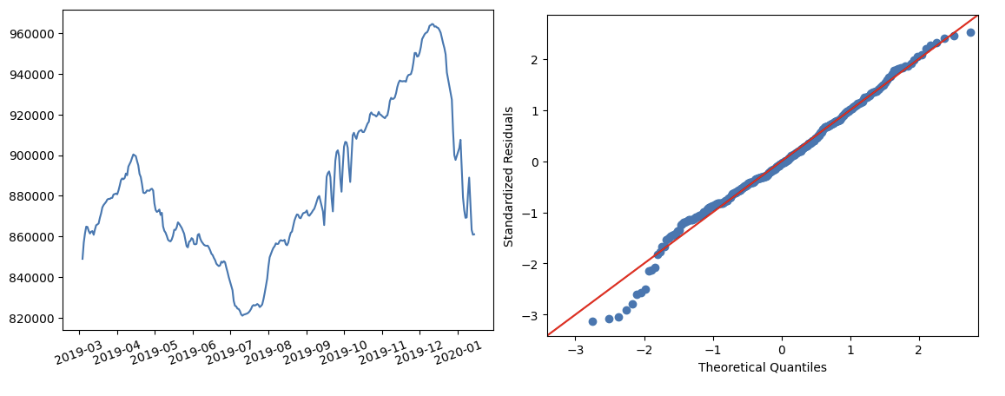
'문제풀이' 카테고리의 다른 글
| 태블로: 개인 과제 풀이 및 해설 정리 (0) | 2024.03.15 |
|---|---|
| 머신러닝: 개인 과제 풀이 및 해설 정리 (1) | 2024.02.05 |
| 파이썬: 개인 과제(필수) 풀이 및 해설 정리 (1) | 2024.01.29 |
| SQL: 개인 과제 풀이 및 해설 정리(필수) (1) | 2024.01.10 |


