시나리오
- 여러분은 S모 금융회사에 입사하였습니다. 올해 프로젝트로 회사의 주 수입원인 이자 매출 증대를 위해서 대출 권유 텔레마케팅을 진행할 예정입니다. 하지만 회사 고객이 1000만명이 넘는 대기업이기 때문에 모든 고객에게 텔레마케팅을 진행하는 것은 비용(돈, 시간)적인 방면에서 효율적이지 못합니다.
- 데이터 분석그룹 소속인 여러분은 마케팅을 효율적으로 수행하기 위한 방안으로 “대출 할 것 같은” 고객을 사전에 선별하라는 지시를 받았습니다. 입사 후 첫 프로젝트이기 때문에 직접 회사 내 데이터로 예측모델링을 수행하기 전에 앞서 포르투칼 은행 데이터 기반으로 파일럿 프로젝트를 수행하여 고객 정보를 바탕으로 대출 실행 예측을 하려 합니다.
데이터 설명 및 출처
- 해당 데이터는 포르투칼 은행이 진행한 전화마케팅 콜을 시행하고 대출 유무 여부를 기록한 데이터 입니다. 총 16개의 변수와 45,211의 관측치를 가지고 있습니다.
· UCI 데이터 저장소: https://archive.ics.uci.edu/dataset/222/bank+marketing
· Github: https://github.com/uci-ml-repo/ucimlrepo
문제1: 라이브러리를 통해 데이터 불러오기
- 다음코드는 데이터를 불러오고 df 변수명에 저장하는 코드입니다.
- github 문서를 읽고 데이터를 요청하여 로컬환경에 저장해보세요.
# 데이터 불러오기
# pip install ucimlrepo
from ucimlrepo import fetch_ucirepo
bank_marketing = fetch_ucirepo(id=222)
# df 변수명에 저장
# df = bank_marketing.data.original #통합 파일만 불러와도 ok
X = bank_marketing.data.features
y = bank_marketing.data.targets
df = pd.concat([X, y], axis=1) #2개 파일 병합할 경우 concat 활용
# csv 파일로 로컬환경에 저장
df.to_csv('bank_marketing.csv', index=False) #불러오기 시 iindex 중복을 막고자 제외 설정
df.head(3)
문제 2: Y 변수 인코딩 적용하기
- Y 라벨을 no,yes를 사용자 정의함수와 apply를 이용하여 0,1로 인코딩 하세요.
- 함수명은 get_binary로 설정하세요.
- Pandas docs: https://pandas.pydata.org/docs/reference/api/pandas.DataFrame.apply.html
def get_binary(x):
"""
주어진 문자열 x가 'no'일 경우 0을 반환하고, 그렇지 않을 경우 1을 반환합니다.
이 함수는 일반적으로 두 가지 범주(예: 'yes'와 'no')를 가진 데이터를 이진 형식(0과 1)으로 변환하는 데 사용됩니다.
Args:
x (str): 변환할 문자열. 'no' 또는 그 외의 값을 가질 수 있습니다.
Returns:
int: 문자열 x가 'no'일 경우 0, 그렇지 않을 경우 1을 반환합니다.
"""
if x == 'no':
return 0
else:
return 1
# y_train 데이터 인코딩 코드
y_train['y'] = y_train['y'].apply(get_binary)
# y_test 데이터 인코딩코드
y_test['y'] = y_test['y'].apply(get_binary)
#잘 적용되었는지 확인
display(y_train[:10])
(추가) 라벨인코더로y값 변환하기
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
le.fit(df_target['y'])
df_target['y_le'] = le.transform(df_target['y']) #숫자는 자동으로 적용됨
문제3: 간단한 모델링 & 평가함수 생성하기
- 평가하기 위한 다음 함수를 완성하세요.
- 필요한 모듈율 불러오고, 학습시키고, 결과를 저장하세요.
- y_pred_train : 훈련데이터 예측결과 변수
- y_pred_test: 테스트데이터 예측결과 변수
def get_score(train:pd.DataFrame, test:pd.DataFrame, x_var_list:list):
""" train과 test 데이터와 X변수 컬럼을 받아 평가지표를 내는 함수입니다.
Args:
train (pd.DataFrame): train 데이터프레임
test (pd.DataFrame): test 데이터프레임
x_var_list (list): 모델링에 사용할 변수 리스트
"""
#외부 전달인자를 내부변수에 할당
X_train = train
X_test = test
#일부 컬럼만 가져오기
X_train = X_train[x_var_list]
X_test = X_test[x_var_list]
#모듈불러오기
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score
#모델가져오기 & 학습하기
model_rf = RandomForestClassifier(random_state=42)
model_rf.fit(X_train, y_train)
# 학습하여 결과 저장
y_pred_train = model_rf.predict(X_train)
y_pred_test = model_rf.predict(X_test)
#평가표 생성
result = pd.DataFrame({'acc' : [accuracy_score(y_train, y_pred_train), accuracy_score(y_test, y_pred_test)],
'f1_score' : [f1_score(y_train, y_pred_train), f1_score(y_test, y_pred_test)]},
index = ['train','test'])
display(result.round(2))
# duration 변수만 사용하여 결과내기
get_score(X_train, X_test, ['duration'])
> 문제 풀이 과정에서 로지스틱회귀 모델만 적용하여 문제에서 제시한 결과 값과 계속 다르게 나옴
: 데이터 분석의 목적은 좋은 모델을 찾아서 예측값을 높이는 것임을 간과하고 하나의 모델 결과값만 수차례 확인
> 추후 각 데이터 특성에 맞는 여러 모델을 한 번씩 돌려보는 연습 필요
(추가) 랜덤포레스트 모델에서 각 변수별 중요도 보는 법
# features 이름과 중요도에 대한 함수 입력
rf.feature_names_in_
rf.feature_importances_
문제4: 모델링 수행하기
- 전체 변수를 가공하여 예측모델링을 수행하는 함수 get_numeric_sc를 완성해보세요.
def get_numeric_sc(X_train:pd.DataFrame, X_test:pd.DataFrame):
"""데이터를 전달받아 수치형 변수 스케일링하는 함수
Args:
X_train (pd.DataFrame): train 데이터프레임
X_test (pd.DataFrame): test 데이터프레임
Returns:
pd.DataFrame, pd.DataFrame: train, test 데이터프레임
"""
# 수치형변수
# age, balance, day_of_week, duration, campaign, pdays,previous
#StandardScaler 적용할 변수 리스트
sc_col = ['pdays','previous']
#MinMaxScaler 적용할 변수 리스트
mm_col = ['age','duration','day_of_week','balance','campaign']
#모듈 불러오기
from sklearn.preprocessing import StandardScaler, MinMaxScaler
#모델 가져오기
#정답은
## 모델은 한 번만 불러와도 됨
## sd_sc = StandardScaler()
## mm_sc_train = MinMaxScaler()
sd_sc_train = StandardScaler()
sd_sc_test = StandardScaler()
mm_sc_train = MinMaxScaler()
mm_sc_test = MinMaxScaler()
#정답은
## 학습과 변환은 동시에!
## X_train[sc_col] = sc.fit_transform(X_train[sc_col])
## X_test[sc_col] = sc.transform(X_test[sc_col])
## X_train[mm_col] = mm.fit_transform(X_train[mm_col])
## X_test[mm_col] = mm.transform(X_test[mm_col])
#train, test 데이터변환(Standard Scaler이용)
sd_sc_train.fit(X_train[sc_col])
X_train[sc_col] = sd_sc_train.transform(X_train[sc_col])
sd_sc_test.fit(X_test[sc_col])
X_test[sc_col] = sd_sc_test.transform(X_test[sc_col])
#train, test 데이터변환(MinMax Scaler이용)
mm_sc_train.fit(X_train[mm_col])
X_train[mm_col] = mm_sc_train.transform(X_train[mm_col])
mm_sc_test.fit(X_test[mm_col])
X_test[mm_col] = mm_sc_test.transform(X_test[mm_col])
return X_train, X_test
X_train, X_test = get_numeric_sc(X_train, X_test)
기타: 문제 코드 복습
1) 데이터 분리
# 제공받은 데이터를 train, test로 분리
X = df.drop(columns = ['y'])
y = df[['y']]
# 학습과 평가를 위해 데이터 셋 분리
# 순서 매우매우 중요
# 기본 test_size = 0.3
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, random_state= 42)
#분리된 데이터 차원 확인
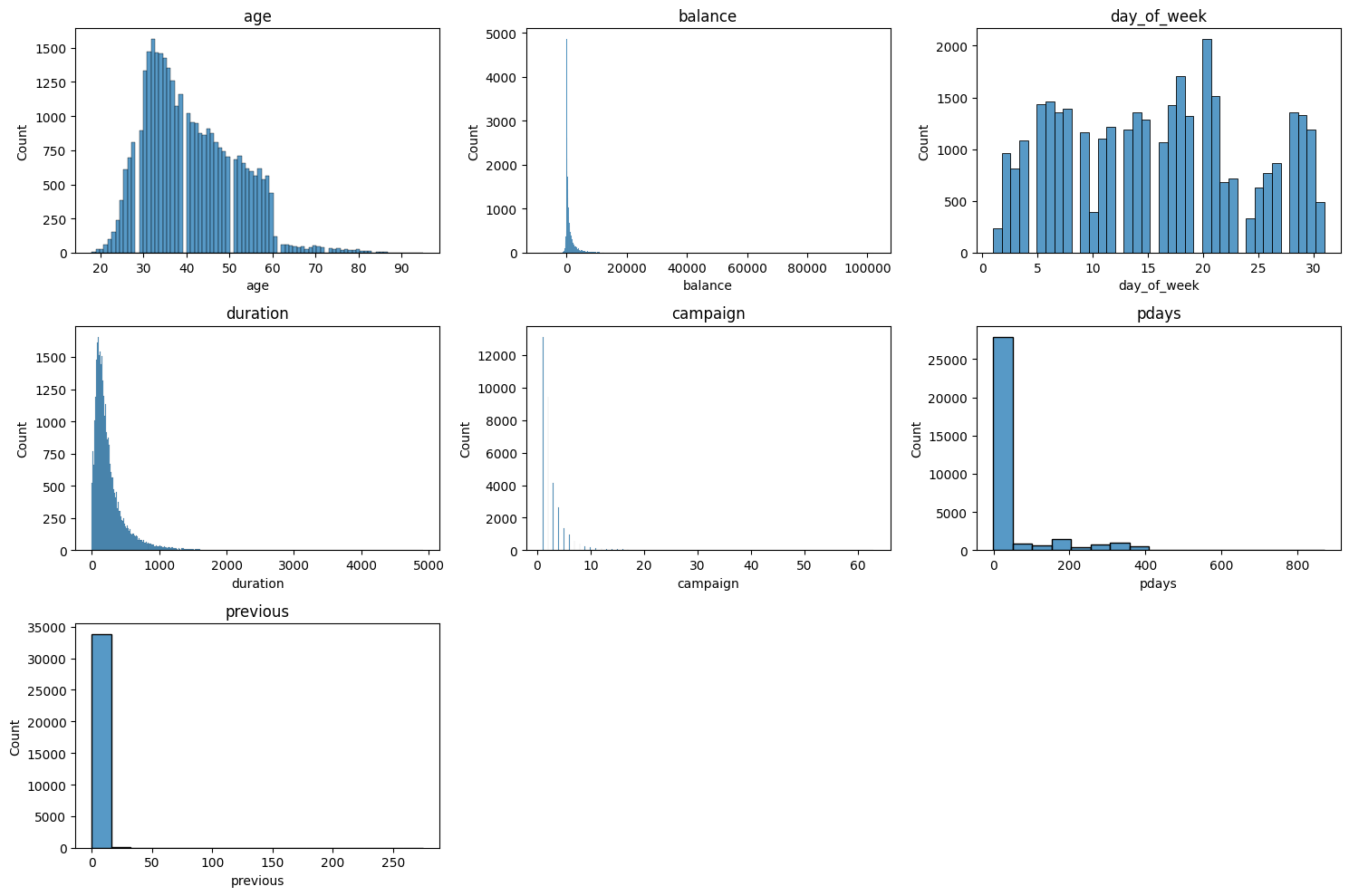
print(X_train.shape, X_test.shape, y_train.shape, y_test.shape)2) 다수의 변수 한 번에 시각화 하는 함수
#수치형 변수 시각화
def get_3_hist(data:pd.DataFrame, columns:list):
""" 데이터와 컬럼을 전달하면 히스토그램을 3개씩 출력해주는 함수
Args:
data (pd.DataFrame): 데이터프레임
columns (list): 컬럼 리스트
"""
# 3열씩 출력되도록 len(columns) 활용
plt.figure(figsize=(15, 5 * (len(columns) // 3)))
for i, col in enumerate(columns):
# 서브플롯 위치 설정(행수, 열수, 위치)
plt.subplot(len(columns) // 3 + (len(columns) % 3 > 0), 3, i + 1)
# 히스토그램 그리기
sns.histplot(data[col])
plt.title(col)
# 전체 그림 표시
plt.tight_layout()
plt.show()
get_3_hist(X_train, numeric_col)
3) 로그스케일 적용
- 로그함수 y = \log_\a x (a>0, a≠1) 는 기본적으로 지수함수 y = a^x (a > 0, a ≠ 1)의 역함수

① x값은 항상 양수(x > 0)
② y값은 실수가 되며, 무조건 (0, 1)을 지남
③ log 밑 값에 따라 그래프가 달라짐
- numpy에서 np.log1p(x) 함수
: 로그 함수는 x=0이면 y는 −∞의 값을 가지므로, x+1을 넣어 x의 0을 1로, y의 −∞값을 0으로 바꿔주는 함수
: np.log(x+1)도 같은 결과값을 보임
# 이상치가 많은 컬럼에 대해서 로그스케일 적용
# 로그스케일 적용을 위해서는 음수가 있으면 안됨
# balance의 음수 값 보정
balance_min = abs(min(X_train['balance'].min(), X_test['balance'].min()))
X_train['balance'] = X_train['balance'] + balance_min
X_test['balance'] = X_test['balance'] + balance_min
# 로그스케일 적용
for col in ['duration','balance','previous']:
X_train[col] = np.log1p(X_train[col])
X_test[col] = np.log1p(X_test[col])4) 범주형 칼럼 더미화 하는 함수
def get_category(X_train:pd.DataFrame, X_test:pd.DataFrame):
""" 데이터를 전달받아 범주형 변수 더미화하는 함수
Args:
X_train (pd.DataFrame): train 데이터프레임
X_test (pd.DataFrame): test 데이터프레임
Returns:
pd.DataFrame, pd.DataFrmae, list: train, test 데이터프레임, 더미화된 컬럼
"""
#범주형변수
# 'job','marital','education','default','housing','loan','contact','month','poutcome'
#범주형 컬럼 더미화 하기
X_train_dummies = pd.get_dummies(X_train[category_col])
X_test_dummies = pd.get_dummies(X_test[category_col])
# 더미화한 변수를 기존 데이터셋에 합치기
X_train = pd.concat([X_train, X_train_dummies], axis = 1)
X_test = pd.concat([X_test, X_test_dummies], axis = 1)
return X_train, X_test, X_train_dummies.columns.to_list()
X_train, X_test, col_dummies = get_category(X_train,X_test)5) test 데이터에 대한 분포 시각화
#train, test 데이터의 라벨 수 세기
y_train_counts = y_train.value_counts()
y_test_counts = y_test.value_counts()
datasets = [(y_train, 'Class Distribution in y_train'),
(y_test, 'Class Distribution in y_test')]
# subplot 생성
fig, axes = plt.subplots(nrows=1, ncols=2, figsize=(6, 3))
# 반복문을 사용하여 각 데이터셋의 클래스 분포 시각화
for i, (dataset, title) in enumerate(datasets):
value_counts = dataset.value_counts()
axes[i].pie(value_counts, labels=value_counts.index, autopct='%1.1f%%', startangle=140)
axes[i].set_title(title)
# 그래프 보여주기
plt.tight_layout()
plt.show()

6) SMOTE 알고리즘을 활용한 oversampling 적용
- y결과값에서 yes(1)의 비중이 적어서 제대로 된 학습이 어려움 > 오버샘플링을 통해 모델 재학습
#최초 1회 실행 후 주석처리
# !pip install imbalanced-learn
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=42)
X_train, y_train = sm.fit_resample(X_train, y_train)
X_test, y_test = sm.fit_resample(X_test, y_test)'문제풀이' 카테고리의 다른 글
| 태블로: 개인 과제 풀이 및 해설 정리 (0) | 2024.03.15 |
|---|---|
| 데이터 분석 기초: 개인 과제 풀이 및 해설 정리 (1) | 2024.01.29 |
| 파이썬: 개인 과제(필수) 풀이 및 해설 정리 (1) | 2024.01.29 |
| SQL: 개인 과제 풀이 및 해설 정리(필수) (1) | 2024.01.10 |


