[머신러닝의 이해와 라이브러리 활용 심화 by 임정 튜터]
1. 데이터 분석(예측모델링) 프로세스 https://datananalysis.tistory.com/71
2. 회귀, 분류 모델링 심화(알고리즘)
1) 의사결정나무(Decision Tree, DT)
: 의사결정규칙을 나무 구조로 나타내어 전체 자료를 몇 개의 소집단으로 분류하거나 예측을 수행하는 분석 방법
- 의사결정나무 시각화 예시 - 타이타닉 데이터 성별 기준

- 주요 명칭
└ 루트 노드(Root Node): 의사결정나무의 시작점. 최초의 분할조건
└ 리프 노드(Leaf Node): 루트 노드로부터 파생된 중간 혹은 최종 노드
└ 분류기준(criteria): sex는 여성 0, 남성 1로 인코딩. 여성이면 좌측 노드로, 남성이면 우측 노드로 분류
└ 불순도(impurity)
· 지니 계수: 불순도 측정 방법 중 하나로 0과 1사이 값으로 구성
· 지니 계수가 0이면 완벽한 순도(모든 샘플이 하나의 클래스), 1은 완전한 불순도(모든 샘플의 균등한 분포)를 의미
· 리프 노드로 갈수록 불순도가 작아지는(한쪽으로 클래스 분류가 잘되는) 방향으로 나무가 자라는 것이 바람직
└ 샘플(samples): 해당 노드의 샘플 개수(891개의 관측치)
└ 값(value): Y변수에 대한 배열. 549명이 죽었고(Y = 0), 342명이 살았음(Y = 1)
└ 클래스(class)
· 가장 많은 샘플을 차지하는 클래스를 표현 (가장 많은 Y의 값)
· 주황색(Y = 0 다수, 죽은 사람이 더 많음 ), 파란색(Y=1 다수, 산 사람이 더 많음)를 표현
- 의사결정나무 정리
└ 장점
· 쉽고 해석하기 용이
· 다중분류와 회귀에 모두 적용이 가능
· 이상치에 견고하며 데이터 스케일링이 불필요(데이터의 상대적인 순서를 고려해서 나뉘므로)
└ 단점
· 나무가 성장을 너무 많이하면 과대 적합의 오류에 빠질 수 있음
· 훈련 데이터에 민감하게 반응하여 작은 노이즈에도 나무의 구조가 크게 달라짐(불안정성)
└ Python 라이브러리
· sklearn.tree.DecisionTreeClassifier
· sklearn.tree.DecisionTreeRegressor
- 코드 작성
# Pclass: LabelEncoder
# Sex: LabelEncoder
# Age: 결측치 -> 평균으로 대체
titanic_df_2 = titanic_df
x_features = ['Pclass', 'Sex', 'Age']
le_class = LabelEncoder()
le_sex = LabelEncoder()
titanic_df_2['Pclass'] = le_class.fit_transform(titanic_df[['Pclass']])
titanic_df_2['Sex'] = le_sex.fit_transform(titanic_df[['Sex' ]])
age_mean = titanic_df['Age'].mean()
titanic_df_2['Age'] = titanic_df_2['Age' ].fillna(age_mean).round(1)
x = titanic_df_2[x_features]
y = titanic_df_2['Survived']
# 의사결정나무 사용하기
# 깊이를 제한하지 않으면 무한히 확장할 수도
model_dt = DecisionTreeClassifier(max_depth=1) #random_state=42 불안정성 보완
model_dt.fit(x, y)
plt.figure(figsize=(10,5))
plot_tree(model_dt, feature_names=x_features, class_names=['Not Survived', 'Survived'], filled=True )
2) 랜덤 포레스트 이론
: 의사결정나무의 과대적합 오류를 보완하기 위해 나무(tree)를 여러 개 만들어 숲(Forest)를 만드는 방법론
: 의사결정나무의 장점은 수용하고 단점은 보완했기 때문에, 성능이 뛰어나 자주 쓰이는 알고리즘
- 배깅(Bagging)의 원리
└ 언제나 머신러닝은 데이터의 부족이 문제
└ 이를 해결 하기 위한 Bootstrapping + Aggregating 방법론

· Bootstrapping: 데이터를 복원 추출*해서 유사하지만 다른 데이터 집단을 생성하는 것 * 뽑고 다시 넣고 반복
· Aggregating: 데이터의 예측,분류 결과를 합치는 것
· Ensemble(앙상블): 여러 개의 모델을 만들어 결과를 합치는 것
(cf) Bootstrap
: “자기 스스로 해낸다”는 뜻으로 신발 뒤꿈치에 달린 끈을 의미하기도.
: 머신러닝에서는 데이터를 복원추출한다는 뜻. 부트스트랩으로 생성한 데이터 샘플들은 모집단의 분포를 유사하게 따라가면서 다양성을 보장해 데이터 부족한 이슈 해결에 도움
- Tree를 Forest로 만들기
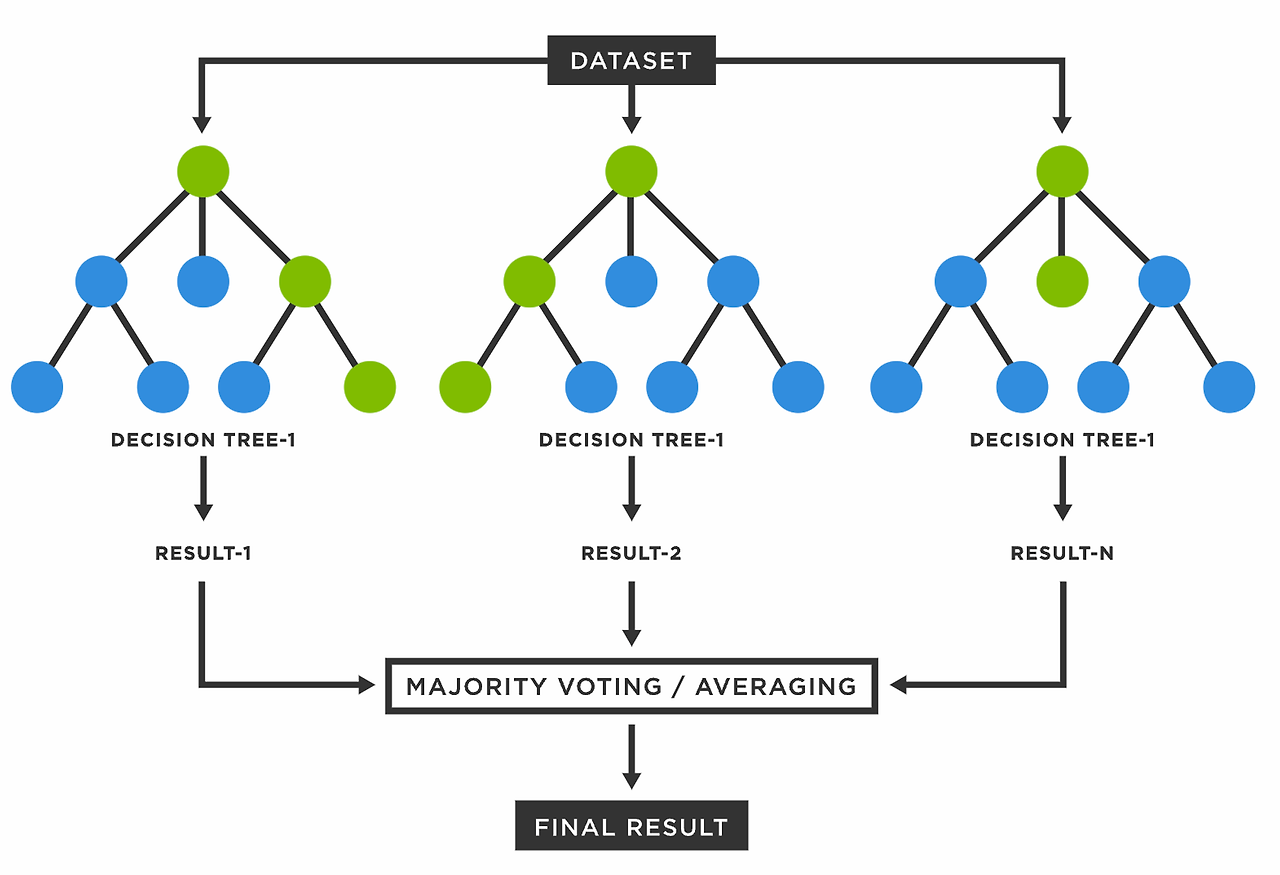
└ 여러 개의 데이터 샘플에서 각자 의사결정트리를 만들어서 다수결 법칙에 따라 결론을 냄
ex) 1번 승객에 대해서 모델 2개는 생존, 모델 1개는 사망을 분류하였다면, 1번 승객은 최종적으로 생존으로 분류
└ 의사결정모델이 훈련 데이터에 민감한 점을 극복
- 랜덤 포레스트 정리
└ 장점
· Bagging 과정을 통해 과적합 회피 가능
· 이상치에 견고하며 데이터 스케일링 불필요
· 변수 중요도를 추출하여 모델 해석에 중요한 특징 파악 가능
└ 단점
· 컴퓨터 리소스 비용이 큼
· 앙상블 적용으로 해석이 어려움
└ Python 패키지
· sklearn.ensemble.RandomForestClassifer
· sklearn.ensemble.RandomForestRegressor
- 코드 작성
# 분류: 로지스틱회귀, 의사결정나무, 랜덤포레스트
from sklearn.linear_model import LogisticRegression
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score
model_lor = LogisticRegression()
model_dt = DecisionTreeClassifier(random_state=42)
model_rf = RandomForestClassifier(random_state=42)
model_lor.fit(x,y)
model_dt.fit(x,y)
model_rf.fit(x,y)
y_lor_pred = model_lor.predict(x)
y_dt_pred = model_dt.predict(x)
y_rf_pred = model_rf.predict(x)
def get_score(model_name, y_true, y_pred):
acc = accuracy_score(y_true, y_pred).round(2)
f1 = f1_score(y_true, y_pred).round(2)
print(model_name, 'acc 스코어:', acc, 'f1 스코어:', f1)
get_score('lor', y, y_lor_pred) # lor acc 스코어: 0.8 f1 스코어: 0.73=
get_score('dt', y, y_dt_pred) # dt acc 스코어: 0.88 f1 스코어: 0.83
get_score('rf', y, y_rf_pred) # rf acc 스코어: 0.88 f1 스코어: 0.84
## 랜덤포레스트의 좋은 점! 변수별 중요도 확인 가능
print(x_features) # ['Pclass', 'Sex', 'Age']
model_rf.feature_importances_ #array([0.17077185, 0.40583981, 0.42338834])
3) 최근접 이웃 (K-Nearest Neighbor, KNN)
: 주변의 데이터를 보고 내가 알고 싶은 데이터를 예측하는 방식
- 최근접 이웃 알고리즘 수행 방법
: 확인할 주변 데이터 K개를 선정한 후, 거리 기준으로 가장 많은 값을 예측 값으로 삼는 것이 KNN의 기본 원리

└ K=3이라면 별 1개와 세모 2개이므로 ? 는 세모로 예측될 것
└ K=7이라면 별 4개와 세모 3개이므로 ?는 별로 예측될 것
└ K값은 대표적인 '하이퍼 파라미터'로 데이터 과학자에 의해 입력되는 외부 구성 변수
- 하이퍼 파라미터의 개념 (K = ?)
└ 파라미터(Parameter): 머신러닝 모델이 학습 과정에서 추정하는 내부 변수이며 자동으로 결정되는 값
· (ex) 선형회귀에서 가중치와 편향 - 머신러닝에서 데이터를 밀어주면 알아서 결정해주는 값
· (동명이함 / 혼동주의) Python에서 함수(def)가 받는 인자(입력 값)를 파라미터라고 하기도 함
└ 하이퍼 파라미터(Hyper parameter): 데이터 과학자가 기계 학습 모델 훈련을 관리하는데 사용하는 외부 구성변수이며 모델 학습과정이나 구조에 영향을 미침
(cf) Data Science 학문과 연관되는 '하이퍼 파라미터'
> 근래의 머신러닝 모델은 정확성과 동시에 복잡성이 증가→ 좋은 결과의 원리 파악이 어려운 경우가 생김
> 하이퍼 파라미터 변수를 조정하면서 실험하고 원리를 밝혀낼 수 있게 되어, Data Science의 기반이 되어줌
> Grid Serch는 하이퍼 파라미터의 변수를 자동으로 조정해주는 것
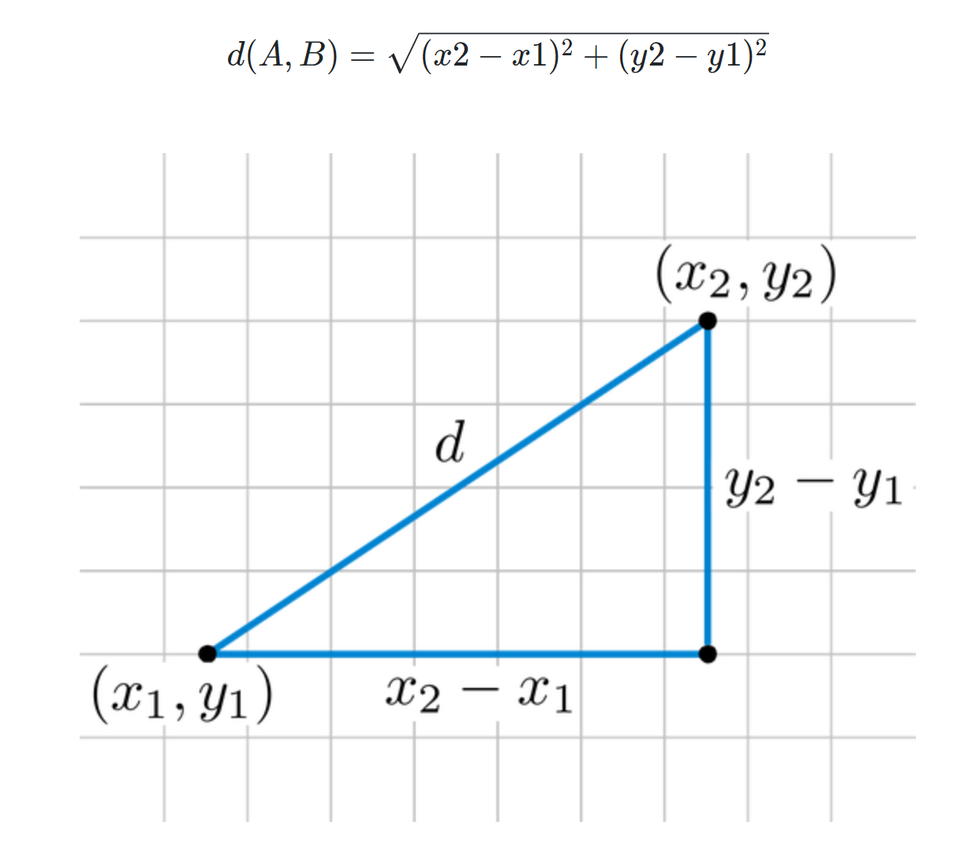
- 거리의 개념 (Nearest = ?)
└ 유클리드 거리(Euclidean Distance) 공식
: 두 점의 좌표를 토대로 직선의 거리를 구하는 식(피타고라스의 정리)
: 이외에도 맨해튼 거리(이동하는 실제 거리 구하는 식) 등 다양한 거리 계산법이 있음
└ KNN 포함 거리기반 알고리즘에서 표준화는 필수
: 거리 기반의 알고리즘은 단위의 영향을 크게 받아 반드시 스케일링-표준화(StandaredScaler)가 필요함
- KNN 모델의 정리
└ 장점
· 이해하기 쉽고 직관적
· 모집단의 가정이나 형태를 고려하지 않음
· 회귀, 분류 모두 가능함
└ 단점
· 차원 수가 많을 수록 계산량이 많아짐 (점과 점 사이의 거리를 모두 구해야 하므로)
· 거리 기반의 알고리즘이기 때문에 피처의 표준화가 필수
└ Python 라이브러리
· sklearn.neighbors.KNeighborsClassifier
· sklearn.neighbors.KNeighborsRegressor
4) 부스팅 (Boosting) 알고리즘
: 여러 약한 학습기(weak learner)를 순차 학습하면서 잘못 예측한 데이터에 가중치를 부여해 오류를 개선해나가는 학습법
: 가장 최신의 알고리즘
(예시) 빨간색과 초록색을 분류하는 문제
> 1개의 선(learner)으로 구별되지 않는 경우가 있음
> 여러 개의 learner를 합친 ensemble을 통해 성능 개선

- 부스팅 알고리즘 종류
① Gradient Boosting Model
└ 특징
· 가중치 업데이트를 경사하강법 방법을 통해 진행
└ Python 라이브러리
· sklearn.ensemble.GradientBoostingClassifier
· sklearn.ensemble.GradientBoostingRegressor
② XGBoost
└ 특징
· 트리기반 앙상블 기법으로, 가장 각광받으며 Kaggle의 상위 알고리즘
· 병렬학습이 가능해 속도가 빠름 (동시에 학습 가능)
└ Python 라이브러리
· xgboost.XGBRegressor
· xgboost.XGBRegressor
③ LightGBM
└ 특징
· XGBoost와 함께 가장 각광받는 알고리즘
· XGBoost보다 학습시간이 짧고 메모리 사용량이 작음
· 작은 데이터(10,000건 이하)의 경우 과적합 발생
└ Python 라이브러리
· lightgbm.LGBMClassifier
· lightgbm.LGBMRegressor
4.2 (실습) 심화모델 실습해보기
의사결정나무와 랜덤포레스트, KNN, 부스팅을 실습해봅시다.
1. 타이타닉 데이터로딩
2. 모델 적용
3. 평가 & 모델별 비교 : x변수 조정을 통해 평가 점수를 높여나갈 수 있음
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import GradientBoostingClassifier
from xgboost import XGBClassifier
from lightgbm import LGBMClassifier
model_knn = KNeighborsClassifier()
model_gbm = GradientBoostingClassifier(random_state=42)
model_xgb = XGBClassifier(random_state=42)
model_lgb = LGBMClassifier(random_state=42)
model_knn.fit(x,y)
model_gbm.fit(x,y)
model_xgb.fit(x,y)
model_lgb.fit(x,y)
y_knn_pred = model_knn.predict(x)
y_gbm_pred = model_gbm.predict(x)
y_xgb_pred = model_xgb.predict(x)
y_lgb_pred = model_lgb.predict(x)
get_score('lor', y, y_lor_pred)
get_score('dt', y, y_dt_pred)
get_score('rf', y, y_rf_pred)
get_score('knn', y, y_knn_pred)
get_score('gbm', y, y_gbm_pred)
get_score('xgb', y, y_xgb_pred)
get_score('lgb', y, y_lgb_pred)
# lor acc 스코어: 0.8 f1 스코어: 0.73
# dt acc 스코어: 0.88 f1 스코어: 0.83
# rf acc 스코어: 0.88 f1 스코어: 0.84
# knn acc 스코어: 0.83 f1 스코어: 0.77
# gbm acc 스코어: 0.86 f1 스코어: 0.8
# xgb acc 스코어: 0.87 f1 스코어: 0.82
# lgb acc 스코어: 0.86 f1 스코어: 0.81
3. 비지도 학습
1) 개요
- 지도학습은 문제(X)와 정답(Y)가 주어지고 문제(X)가 주어졌을때 정답(Y)을 맞추는 학습
- 비지도 학습은 답(Y)을 알려주지 않고 데이터 간 유사성을 이용해서 답(Y)을 지정하는 방법
└ 데이터를 기반으로 레이블링을 하는 작업으로 답이 없어 어렵고 주관적인 판단이 개입됨
- 비지도 학습 예시: 고객 특성에 따른 그룹화(ex. 헤비유저, 일반유저), 구매 내역별 그룹화(ex. 생필품 구매)
- 대표적인 알고리즘: K-Means clustering, 이 외 Gaussian Mixture Model(GMM), DBSCAN 등
- 붓꽃 데이터(iris)를 이용한 군집화 예시
① Labeling이 안된 꽃 받침 길이-너비 산점도

② Labeling이 된 꽃 받침 길이 - 너비 산점도

③ (스포) K-means Clustering를 이용한 군집화

2) K-means Clustering K-평균 알고리즘 )
▶ K-Means Clustering 수행 순서

① 임의로 K개의 군집 수 설정
② 임의의 중심을 선정
③ 해당 중심점과 거리가 가까운 데이터를 그룹화

④ 데이터의 그룹의 무게 중심으로 중심점을 이동
⑤ 중심점을 이동했기 때문에 다시 거리가 가까운 데이터를 그룹화
(3~5번 반복 & K개수 조정하면서 최적의 결과 도출)
▶ K-Means Clustering 장단점 및 라이브러리
- 장점
└ 일반적이고 적용하기 쉬움
- 단점
└ 거리 기반으로 가까움을 측정하기 때문에 차원이 많을 수록 정확도가 떨어짐
└ 반복 횟수가 많을 수록 시간이 느려짐
└ 몇 개의 군집(K)을 선정할지 주관적임
└ 평균(중심점) 을 이용하기 때문에 이상치에 취약함
- Python 라이브러리
└ sklearn.cluster.KMeans
└ 함수 입력 값
· n_cluster: 군집화 갯수
· max_iter: 최대 반복 횟수
└ 메소드
· labels_: 각 데이터 포인트가 속한 군집 중심점 레이블
· cluster_centers: 각 군집 중심점의 좌표
3) 군집평가 지표
▶ 실루엣 계수
: 실루엣 분석(silhouette analysis)이란 간 군집 간의 거리가 얼마나 효율적으로 분리되어 있는지 측정
: 군집화가 잘되어 있다는 것은 다른 군집간의 거리는 떨어져 있고 동일한 군집끼리는 가까이 있다는 것을 의미

- 실루엣 계수 수식
$$ S(i) = \frac{b(i)-a(i)}{max(a(i),b(i))} \ 단\ i는 데이터 $$
└ 수식 해석: 떨어져 있는 거리($b(i) -a(i)$)를 구하고, 단위 정규화를 위해 $a(i), b(i)$ 중에 큰 값으로 나누기
└ 결과 해석: 1로 갈수록 변수 간 거리가 길어 근처 군집과 더 멀리 떨어짐. 0에 가까울수록 근처 군집과 가까워 진다는 것
- 좋은 군집화의 조건
└ 실루엣 값이 높을수록(1에 가까움)
└ 개별 군집의 평균 값의 편차가 크지 않아야 함
- Python 라이브러리
└ sklearn.metrics.sihouette_score: 전제 데이터의 실루엣 계수 평균 값 반환
└ 함수 입력 값
· X: 데이터 세트
· labels: 레이블
· metrics: 측정 기준 기본은 euclidean
4) (실습) 붓꽃 데이터를 이용한 군집화
① 붓꽃데이터 load
② Kmeans Clustering
③ 시각화 결과 비교
④ 군집화 평가
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import sklearn
iris_df = sns.load_dataset('iris')
iris_df.head(3)
iris_df.info()
iris_df.describe()
#선점도 확인
sns.scatterplot(data=iris_df, x='sepal_length', y='sepal_width')
# 종별로 보려면 hue를 넣어주면 됨
sns.scatterplot(data=iris_df, x='sepal_length', y='sepal_width', hue='species')
## 군집화
# 데이터 복사
iris_df_2 = iris_df.drop('species', axis=1) # 데이터 복사
# 알고리즘 불러와서 학습
from sklearn.cluster import KMeans
#n_clusters는 필수 파라미터(디폴트 auto)
kemans = KMeans(n_clusters = 3, init='k-means++', max_iter=300, random_state=42)
kemans.fit(iris_df_2)
# 실제값과 군집값 칼럼추가
iris_df_2['target'] = iris_df['species']
iris_df_2['cluster'] = kemans.labels_ # kemans.labels_ 군집한 결과값
iris_df_2.info()
# 군집 시각화
plt.figure(figsize=(12,6)) #그래프 사이즈
# subplot(nrows, ncols, index) / 디폴트 1, 1, 1
# row는 행, col는 열, index는 위치! rowXcol 그래프에 위치는 어디인지 표기하는 것
plt.subplot(1,2,1) #1x2 에서 1번 위치
sns.scatterplot(data = iris_df_2, x ='sepal_length', y='sepal_width', hue = 'target')
plt.title('Original')
plt.subplot(1,2,2) #1x2 에서2번 위치
sns.scatterplot(data = iris_df_2, x='sepal_length', y='sepal_width', hue = 'cluster')
plt.title('K-means Clustering')
plt.show()
3) (실습) 고객 세그멘테이션
- 고객 세그멘테이션(Customer Segmentation)의 정의
: 다양한 기준으로 고객을 분류하는 기법
주로 타겟 마케팅이라 불리는 고객 특성에 맞게 세분화 하여 유형에 따라 맞춤형 마게팅이나 서비스를 제공하는 것을 목표
비지도 학습이 가장 많이 사용되는 분야는 고객 관계 관리(Customer Relationship Management, CRM)분야

- RFM의 개념
└ Recency(R) 가장 최근 구입 일에서 오늘까지의 시간
└ Frequency(F): 상품 구매 횟수
└ Monetary value(M): 총 구매 금액
- (실습) Oneline_Retail 데이터를 활용한 고객 세그멘테이션
① UCI 데이터 세트 다운로드 https://archive.ics.uci.edu/dataset/352/online+retail
└ retail_df.head()

└ retail_df.info()

② EDA
③ 데이터전처리
└ customerID 결측치 삭제
└ InvoiceNo, UniPrice, Quantity 데이터확인 및 삭제
└ 영국데이터만 취함
④ RFM 기반 데이터 가공
└ 날짜 데이터 가공
└ 최종목표

· StandardScaler 적용
⑤ 고객 세그멘테이션
⑥ 평가
(1) 정규화 진행 후 K-menas를 통한 군집화
- 실루엣 계수 : 0.592로 높은 편이나, 시각화 시 군집이 불균형한 것으로 확인

(2) log 스케일링을 통한 추가 전처리 후 K-menas 군집화 결과
- 실루엣 계수 : 0.300으로 낮아졌으나, 시각화 시 군집이 더 균형을 이룬 것으로 확인
- 군집을 몇 개로 어떻게 나눌 건지는 도메인 맥락이나 내부 사정 등을 잘 고려해서 진행해야

- 전체 코드
retail_df = pd.read_excel('D:/phython/ML/Online Retail.xlsx')
retail_df.head(3)
retail_df.info()
retail_df.isnull().sum()
## 데이터 전처리 전략 ##
# 1. 결측치 삭제: customerID (406829/541909)
# 2. 데이터확인 및 삭제: Invoice가 C로 시작 or UnitPrice < 0 or Quantity < 0 은 취소로 추정
# 3. 필터링: 영국데이터만 취함 > 대부분 영국 데이터(495478 / 541909)
retail_df.describe(include='all')
# 1. 결측치 삭제: customerID (406829/541909)
cond_cust = (retail_df['CustomerID']).notnull() #null이 아닌 것 조건
retail_df[cond_cust].isnull().sum() #조건 적용 확인
# 2. 데이터확인 및 삭제: Invoice가 C로 시작 or UnitPrice < 0 or Quantity < 0 은 취소로 추정
cond_invo = (retail_df['InvoiceNo'].astype(str).str[0] != 'C')
retail_df[cond_invo].info()
cond_minus = (retail_df['UnitPrice'] > 0) & (retail_df['Quantity'] > 0)
retail_df[cond_minus].info()
# 3. 필터링: 영국데이터만 취함 > 대부분 영국 데이터(495478 / 541909)
cond_uk = (retail_df['Country'] == 'United Kingdom')
retail_df[cond_uk].info()
retail_df[cond_uk]['Country'].value_counts()
# 1~3 합치기
retail_df_2 = retail_df[cond_cust & cond_invo & cond_minus & cond_uk]
retail_df_2
## RFM 구하기 ##
# Recency(R): 가장 최근 구입 일에서 오늘까지의 시간
## InvoiceDate 날짜형으로 바꾸기
## (InvoiceDate의 max값 + 1)을 오늘로 설정(2011-12-10). 최근 구매일 빼면 1일이 되도록
# Frequency(F): InvoiceNo 개수 세기
# Monetary value(M): Quantity*UnitPrice 더하기
# Recency(R)
# 고객별 구매액 확인
retail_df_2[['CustomerID']].drop_duplicates() # unique CustomerID 추출
retail_df_2.pivot_table(index='CustomerID', values='Amt', aggfunc='sum').sort_values('Amt', ascending=False)
import datetime as dt
# 2011.12.10 기준 각 날짜를 빼고 + 1
# retail_df_2['InvoiceDate'].max() # Timestamp('2011-12-09 12:49:00')
# 추후 CustomerID 기준으로 최소 Priod를 구하면 그것이 Recency
# 즉, 1번 사람이 100일전, 20일전, 5일전 구매했다면, [5일전] 구매한 최신 데이터를 불러와야 함
retail_df_2['Priod'] = (dt.datetime(2011, 12, 10) - retail_df_2['InvoiceDate']).apply(lambda x: x.days + 1)
# 오늘 날짜에서 최신 데이터를 뺀 다음
# 각 행별로 적용해줘라(apply), day를 하루씩 추가
retail_df_2.head(3)
# Monetary(M)
retail_df_2['Amt'] = (retail_df_2['Quantity'] * retail_df_2['UnitPrice']).astype('int')
retail_df_2
# RFM
rfm_df = retail_df_2.groupby('CustomerID').agg({
'Priod': 'min',
'InvoiceNo' : 'count',
'Amt' : 'sum'
})
rfm_df.columns = ['Recency', 'Frequency','Monetary']
rfm_df
# 히스토그램으로 결과 확인 #너무 치우쳐져 있음
sns.histplot(rfm_df['Recency'])
sns.histplot(rfm_df['Frequency'])
sns.histplot(rfm_df['Monetary'])
# RFM이 너무 쏠려 있어, 스케일링 - 데이터 정규화 진행
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
X_features = sc.fit_transform(rfm_df[['Recency', 'Frequency','Monetary']])
# 군집화 진행
from sklearn.cluster import KMeans
from sklearn.metrics import silhouette_score
kmeans = KMeans(n_clusters= 3, random_state=42)
labels = kmeans.fit_predict(X_features)
rfm_df['label'] = labels
silhouette_score(X_features, labels) #0.592
# 실루엣 계수 시각화 함수 활용 #시각화 결과 군집이 불균형
from kmeans_visaul import visualize_silhouette
visualize_silhouette([2,3,4,5,6], X_features)
# log 스케일을 통한 추가 전처리
import numpy as np
rfm_df['Recency_log'] = np.log1p(rfm_df['Recency'])
rfm_df['Frequency_log'] = np.log1p(rfm_df['Frequency'])
rfm_df['Monetary_log'] = np.log1p(rfm_df['Monetary'])
X_features2 = rfm_df[['Recency_log','Frequency_log','Monetary_log']]
sc2 = StandardScaler()
labels2 = kmeans.fit_predict(X_features2)
X_features2_sc = sc2.fit_transform(X_features2)
silhouette_score(X_features2, labels2) # 0.30073570858688
visualize_silhouette([2,3,4,5,6], X_features2)
# 실루엣 계수는 감소했으나 시각화 모양은 균형적으로 조정됨
4. 딥러닝
1) 개요
① 딥러닝 이론
▶ 머신러닝 vs 딥러닝
- 공통점
: 데이터로부터 가중치를 학습해 패턴을 인식하고 결정을 내리는 알고리즘 개발과 관련된 인공지능(AI)의 하위 분야
- 차이점
: 머신러닝은 데이터 안의 통계적 관계를 찾아내며 예측이나 분류를 하는 방법
: 딥러닝은 머신러닝의 한 분야로 신경세포 구조를 모방한 인공 신경망을 사용하며 자연어와 이미지 처리가 뛰어남

▶ 딥러닝의 유래
- 인공 신경망(Artificial Neural Networks): 인간의 신경세포를 모방하여 만든 망(Networks)
└ 신경세포는 이전 신경세포로부터 들어오는(input) 전기신호 자극을 다음 신경세포로 전달하는(output) 기능을 하는 세포

- 퍼셉트론(Perceptron): 인공 신경망의 가장 작은 단위
- 몸무게와 키 데이터 예시
* 선형회귀식
$$ \hat{Y} = w_0 + w_1X $$
$$ Y = w_0 + w_1X +b $$
* 임의로 $w_0 \ w_1$ 100과 1로 설정
| 키(Y) | 몸무게(X) | 예측키 = 키 *1 +100 |
편향(Bias) = 키(Y) - 예측키 |
| 187 | 87 | 187 | 0 |
| 176 | 81 | 181 | -7 |
| 168 | 66 | 166 | +2 |

▶ 가중치weight를 구하는 방법은? Gradient Descent(경사 하강법)
- 회귀 문제에서 최소화 하려는 값은? Mean Squared Error(MSE)
└ MSE는 에러을 제곱한 총합의 평균으로, 궁극적으로 에러이기 때문에 값을 줄이는 것이 중요
└ 가중치를 이리 저리 움직이면서 최소화 하는 값(MSE)이 바로 목적 함수 혹은 손실 함수(cost function)
- 경사 하강법(Gradient Descent)
: 모델의 손실 함수를 최소화하기 위해 모델의 가중치를 반복적으로 조정하는 최적화 알고리즘
: 가중치를 찾기 위한 직관적이고 빠른 계산 방법
: 변수 X가 여러 개 있다면 동시에 여러 개의 값을 조정하면서 최소의 값을 찾을 수 있음
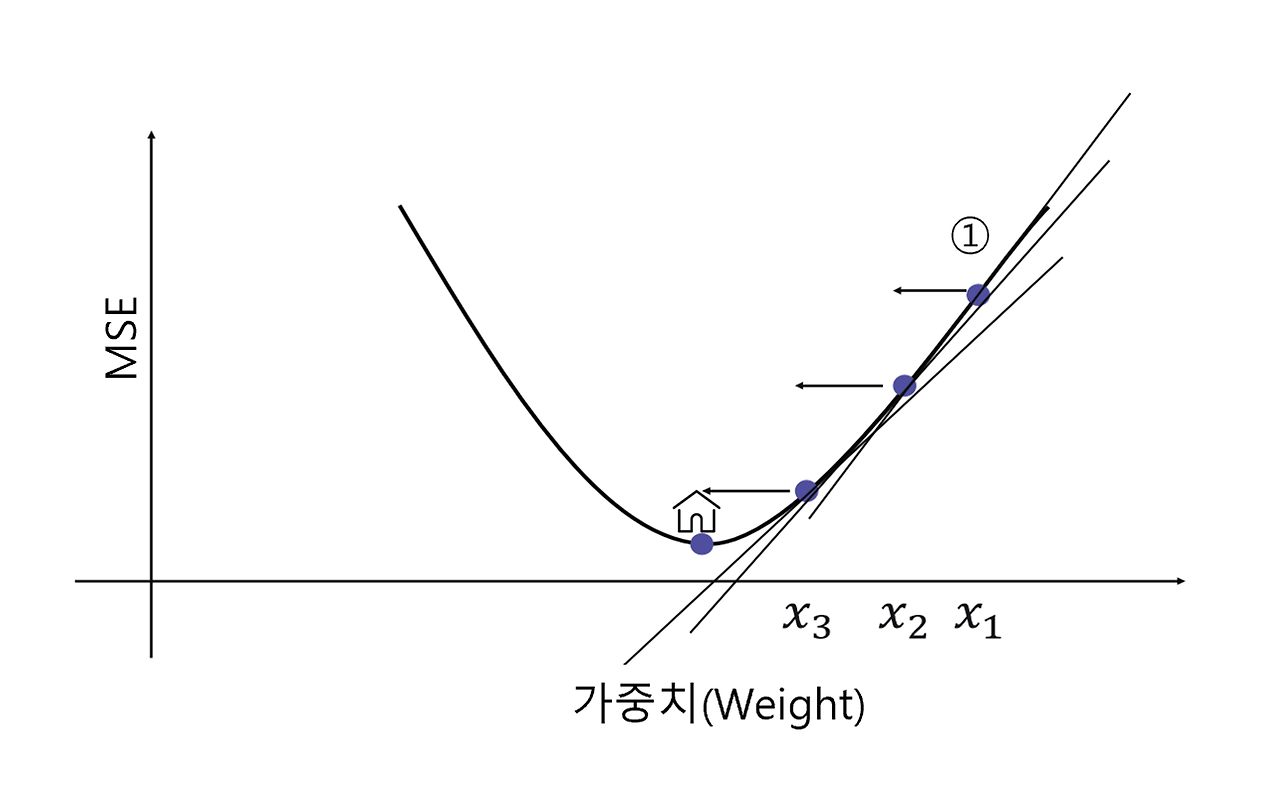
$$
x_{i+1} = x_i - \alpha * \nabla f(x) \\
\alpha : step \ size \\
\nabla f(x): \ 기울기
$$
: 기울기 만큼 가중치를 변화 시키면서 값을 찾는데, 이때 알파 값(a.k.a 러닝 메이트)에 따라 증감 폭을 정할 수 있음
· 알파값은 대표적인 하이퍼 파라미터로, 값이 너무 크면 보폭이커서 최저치를 못 찾을 수도 있음
- 경사하강법에는 배치 경사하강법, 확률적 경사하강법 등 다양하게 개발된 알고리즘이 있음
▶ 활성화 함수의 등장
: 타이타닉 문제에서 사망,생존과 같은 비선형적 분류를 만들기 위해 활성화 함수(Acitvation Fucntion)을 사용하게 됨
: 로지스틱회귀에서 나온 로지스틱 함수 역시 활성화 함수의 한 예
- 활성화 함수를 적용한 분류 도식화

- 로지스틱 함수(시그모이드 함수의 한 예) 외에도 다양한 활성화 함수가 존재

▶ 히든 레이어의 등장
: 비선형 데이터 변환과 동시에 데이터의 고차원적 특성(ex 이미지, 자연어) 학습이 필요해짐
: 고차원 학습을 위해 중간에 입력과 결과 외의 숨은 층(Hidden Layer)을 추가하면서 히든 레이어 개념이 등장
: 단, 인공 신경망의 학습 과정 때문에 기울기 소실 문제 발생

▶ 기울기 소실 문제 등장
- 인공 신경망의 학습의 2가지 과정
· 순전파(Propagation): 입력 데이터가 신경망의 각 층을 통과하면서 최종 출력까지 생성되는 과정
· 역전파(Backpropagation): 신경망의 오류를 역방향으로 전파하여 각 층의 가중치를 조절하는 과정
- 문제: 역전파 과정에서 하위 레이어로 갈수록 오차의 기울기가 점점 작아져 가중치가 거의 업데이트 되지 않는 현상
- 해결: 특정 활성화 함수(ex Relu)를 통해 완화하게 됨

* 각 명칭에 대한 정리
- Input Layer: 주어진 데이터가 벡터(Vector)의 형태로 입력됨
- Hidden Layer: Input Layer와 Output Layer를 매개하는 레이어로 이를 통해 비선형 문제를 해결할 수 있게 됨
- Output Layer: 최종적으로 도착하게 되는 Layer
└ Activation function(활성화 함수): 인공신경망의 비선형성을 추가하며 기울기 소실 문제 해결함
▶ 복습은 도움이 된다 - epoch
: 딥러닝도 동일한 데이터에 대해 여러 번 공부함. batch size로 러닝하고 업데이트, 다시 batch size로 러닝 후 업데이트 반복

$$ Epoch = batch \ * iteration $$
- epoch: 전체 데이터가 신경망을 통과하는 한 번의 사이클 (ex. 1000 epoch: 데이터 전체 1000번 학습)
- batch: 전체 훈련 데이터 셋을 일정한 크기의 소 그룹으로 나눈 것
- iteration: 전체 훈련 데이터 셋을 여러 개(=batch)로 나누었을 때 배치가 학습되는 횟수
- 요약: 1000개의 데이터 batch size 100개라면, 1 epoch에는 iteration은 10번 일어나며 가중치 업데이트도 10번 진행
② (실습) 딥러닝
- 딥러닝 패키지
└ Tensorflow: 구글이 오픈소스로 공개한 기계학습 라이브러리
· 2.0 버전부터는 딥러닝 라이브러리를 구축하는 Keras 패키지와 통합
└ Pytorch: 메타(전 페이스북)가 개발한 토치(torch) 기반의 딥러닝 라이브러리
* 실습에서는 Tensorflow와 keras 활용
- Tensorflow 패키지 이해
└ tensorflow.keras.model 함수 링크 https://www.tensorflow.org/api_docs/python/tf/keras/Model#fit
└ tensorflow.keras.model.Sequential
· model.add: 모델에 대한 새로운 층을 추가함
º unit
· model.compile: 모델 구조를 컴파일(작성, 확)하며 학습 과정을 설정
º optimizer: 최적화 방법, Gradient Descent 종류 선택
º loss : 학습 중 손실 함수 설정
- 회귀: mean_squared_error(회귀)
- 분류: categorical_crossentropy
º metrics : 평가척도
- mse: Mean Squared Error
- acc : 정확도
- f1_score: f1 score
· model.fit: 모델을 훈련 시키는 과정
º epochs: 전체 훈련 데이터 셋에 대해 학습을 반복하는 횟수 (얼마나 공부할 것인지)
· model.summary(): 모델의 구조를 요약하여 출력
└ tensorflow.keras.model.Dense: 완전 연결된 층
· unit: 층에 있는 유닛의 수. 출력에 대한 차원 개수
· input_shape: 1번째 층에만 필요하면 입력데이터의 형태를 지정
└ model.evaluate: 테스트 데이터를 사용하여 평가
└ model.predict: 새로운 데이터에 대해서 예측 수행
- 코드 예시
!pip install tensorflow
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
import numpy as np
from sklearn.preprocessing import StandardScaler
weights = np.array([87,81,82,92,90,61,86,66,69,69])
heights = np.array([187,174,179,192,188,160,179,168,168,174])
# Sequential 모델 초기화
model = Sequential()
# 단일을 추가하기
dense_layer = Dense(units = 1, input_shape = [1])
model.add(dense_layer)
# 아담이라는 모델을 활용해 mse 값을 최소화 하라
model.compile(optimizer='adam', loss = 'mean_squared_error')
model.summary() # x값, 가중치 포함해서 파라미터는 2개
# 학습시키기 # loss 값도 나옴
model.fit(weights, heights, epochs = 100)
# 히든 레이어를 포함한 아키텍처
model2 = Sequential()
model2.add(Dense(units=64, activation = 'relu', input_shape=[1]))
model2.add(Dense(units=64, activation = 'relu'))
model.add(Dense(units=1))
model2.compile(optimizer='adam', loss = 'mean_squared_error')
model2.summary()
model2.fit(weights, heights, epochs = 100)
2) 딥러닝의 활용 예시
① 딥러닝의 예시 - 자연어처리
▶ 가장 간단한 자연어처리
- 자연어처리(Natural Language Processing) 개념: 인간의 언어를 데이터화 하는 것
ex) 단어의 빈도 수 기반 데이터 화(Bag of Words)


▶ 최신 자연어 처리 모델 - LLM
- 최근에는 빅테크들이 각자의 LLM(Large Language ModeL)을 개발해서 서비스화 하는 중
- LLM의 종류: GPT-4(OpenAI), PaLM2(Google), LlaMA(Meta)
② 딥러닝의 예시 - 이미지
: 이미지는 색깔이 이미 데이터! 합성 곱 연산을 통해 딥러닝 모델에 학습하고 이미지를 생성하는 방식으로 발전
▶이미지는 원래 데이터 기반
- 이미지도 RGB 256개의 데이터로 이루어진 데이터의 집합
- 3차원 데이터를 모델에 학습 시킴
ex) 숫자 2를 예측하는 딥러닝의 구조

ex) 합성 곱(CNN) 연산의 예시

▶ 최신 이미지 생성 딥러닝
- 최근의 이미지 모델은 Mutimoda
: 단순 이미지 외에도 텍스트, 음성 등 다양한 유형의 데이터를 함께 사용
: 특히 Stable Diffusion은 커뮤니티가 발달해 쉽게 설치할 수 있어 접근성도 뛰어남

3) 강의 마무리
[ 단원별 한 줄 요약 ]
1. 머신러닝의 기초
- 머신러닝의 기본, 개념
2. 회귀분석
- 가장 설명을 잘하는 직선을 그리는 법 - 선형회귀
- 실제 값과 예측 값의 오차를 계산하라 - Mean Squared Error
3. 분류분석
- 특정 범주에 대한 확률 예측하기 - 로지스틱회귀
- 맞춘 것에 대한 지표: 정확도, f1_score
4. 데이터 분석 프로세스
- 데이터 수집 → 전처리 → 모델링 → 평가
5. 회귀, 분류 모델링 심화
- 의사결정을 기반으로 한 모델 - 의사결정나무
- 나무를 여러 개 만들어서 다수결 원칙을 사용하자 - 랜덤포레스트
- 유유사종의 원리로 예측하자 - KNN
- 약한 학습기를 여러 개 합치자 - 부스팅 모델
6. 비지도학습
- 만약 Y(정답이 없다면) 특성을 이용해 그룹화 하자 - K-means 군집화
7. 인공 신경망
- 사람의 신경세포를 모방한 네트워크 - 인공 신경망
[ 데이터 직군별 머신러닝 활용 방안 ]
- Data Engineer : ML/DL 활용 낮음
└ 데이터 Extract(추출), transform(변환), Load(적재) 및 데이터 파이프라인 관리
└ Workflow 과정 자동화
- Machine Learning Engineer : ML/DL 활용 필수
└ 데이터를 기반으로 모델 최적화
└ 개발한 모델을 실제 운영에 배포, 성능 평가, 유지 보수
- AI Researcher: ML/DL 활용 필수
└ 머신러닝/딥러닝 모델을 논문을 통해 읽고 구현
└ 논문 작성 및 발표
- Data Analyst: ML/DL 활용 중간
└ 데이터 분석 및 인사이트 도출
└ 보고서 작성 및 데이터 시각화 ex) A/B test, 유저분석
└ ML/DL 활용: 고객 세분화(클러스터링), 고객 이탈 분석(판매량 예측), 텍스트 분석(자연어 처리를 이용한 리뷰 분석)
'TIL' 카테고리의 다른 글
| [240206] 중첩 딕셔너리? JSON 포맷 데이터프레임으로 평면화 (0) | 2024.02.06 |
|---|---|
| [240205] SQL: 코드카타 119~121 & 파이썬: 코드카타 29~30 (0) | 2024.02.05 |
| [240201] 머신러닝 - EDA, 데이터 전처리(이상치/결측치/인코딩/스케일링/데이터분리) (1) | 2024.02.01 |
| [240131] SQL: 코드카타 118 & 파이썬: 코드카타 28 (0) | 2024.01.31 |
| [240130-31] 머신러닝 - 선형회귀, 로지스틱회귀 (1) | 2024.01.31 |

